I’m Linus’s fan. This guy created an open-source operating system running everywhere, co-authored a book which is one of my favorites, and built a distributed version control system used by almost every developer everyday. I switched to Git the moment I met it, fascinated by its speed and elegance. A version control system is what developers use to manage source code, so they can keep the track of code updates, share modifications with friends and colleagues, rollback to a previous bug-free version when something new goes wrong, etc. Git made life much more enjoyable, I hope CKB can do the same.

CKB is Git
Git inspires the idea of the Cell model and CKB. Although Git is invented out from Linus’s eager desire for the convenience of Linux kernel development, people use it whenever they want to organize something, from notes to blog posts to pictures. It’s a knowledge base with excellent history tracking support. A git knowledge base is called a ‘repository’, it maintains an immutable append-only object database (does it ring a bell?) internally. The basic storage unit in Git is Blob (binary large object) which is just an object contains the data people stores in the repository, just like a cell in CKB. A blob object is created for each version of each file. Whenever you create a new file, you create a new blob. Whenever you modify an existing file, you create a new blob with modified content, leave the old blob untouched (sounds familiar?). Every blob is hashed and the blob hash is used as the identifier to reference a blob. After a few hours of work you created some new files and modified some existing files, you commit all the changes into the repository, synchronize the new commit to peers and call it a day. A commit is the basic history point in Git, the repository history consists of a series of commits, from the genesis of the repository to its latest update. A commit is a version of the repository at some certain time, including version metadata like author, timestamp, parent commit, and reference to a tree of blobs. Just like the block header keeps the metadata for each update of a blockchain, by writing down miner address, timestamp, parent hash, and the root of the transaction merkle tree. You and your colleagues keep extending the history of a git repository to get paid like miners keep extending the history of blocks to get block reward.
A git repository can have forks too. People work on different forks, but which fork is the “right” one is chosen by the repository maintainer, not by consensus. Git is a distributed system without consensus, relies on ad-hoc peer-to-peer communication such as ssh or email for data exchange. The resemblance between Git and blockchain means, with cautiousness we should be able to incorporate the idea of Git without introducing conflicting design choices into a blockchain, so the blockchain or smart contract developer can enjoy some of the proven merits of Git. That’s what CKB looks like under the cover, a sole huge Git repository with real p2p network, global consensus, and enhanced blobs, being constantly updated by a swarm of anonymous.
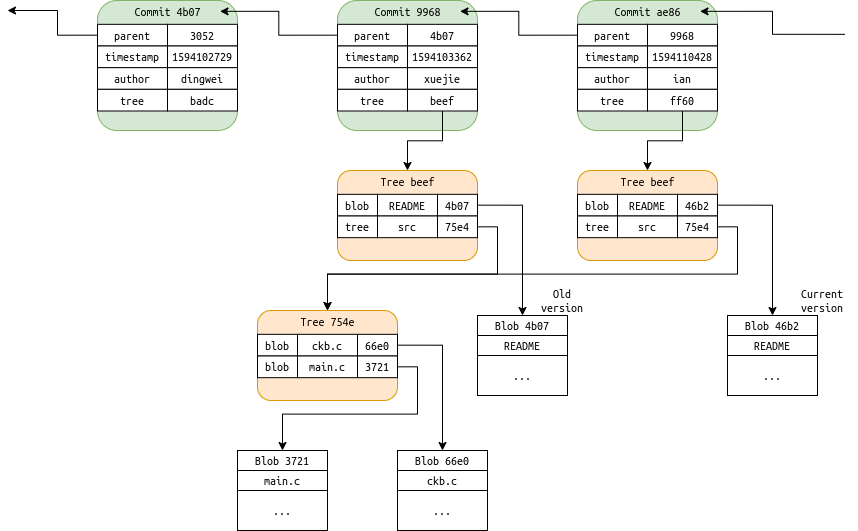
Figure 1. This is not a blockchain.
Name The Cell You Like
At the core of both Git and CKB is data objects (blob/cell) and hash references. A hash reference is the inherent name of an object, a magic wand you can wield to extract the value of data. If you can speak an object’s name, you can harness its power. On CKB the code and user data of a smart contract are separated, so the hash reference allows you to name a piece of code or user data directly, make them first-class objects in the system. This fine granularity creates a flexible and powerful programming model. Here’re some examples.
Code/Data Reuse
Because a cell is a referencable storage unit, code/data reuse on CKB is easy. Suppose there’s some shared code/data stored in the cell 0xbeef#1 (the output 1 of transaction 0xbeef). To reuse it, first load the cell 0xbeef#1 as a transaction dependency (cell_deps), then read data from it with ckb_load_cell_data syscall, as the default lock script demonstrated. Once the data in cell 0xbeef#1 is loaded into VM memory, it can be treated either as code or data, depends on your need. This way CKB works like a shared repository of code and data for smart contracts running on it. Isn’t it cool if we can build a smart contract by combining existing secure legos? There’s no need to copy the code from somewhere on Github and deploy the same code again and again, which is a waste of both your time and on-chain space. The analysis of Ethereum contracts [1] [2] shows 95%~99% of them are duplicates.

Figure 2. Most duplicated smart contracts on Ethereum.
Dependency-Kill Resistance
In the above code/data reuse example, you don’t need to worry that someone modifies the code/data stored in the dependency cell because cells are immutable, i.e. there’s no way to modify it. But what if the dependency cell owner simply remove it from CKB? Wouldn’t that make my smart contract unusable?
That’s true on Ethereum. If you have been in this space long enough you probably know the accidental bust of 280 million USD in 2017. The whole tragedy is triggered by the accidental deletion of an Ethereum smart contract which is used by many other smart contracts. The deletion caused all dependent smart contracts dysfunction and all assets stored in them froze.
Such an accident is no big deal on CKB, as anyone who keeps a copy of the code (e.g. those runs full node or sophisticated light client) can deploy the same code on-chain again and the code hash reference will still work. Just use the new dependency cell to construct your transactions. No one would be hurt, everything would be fine.
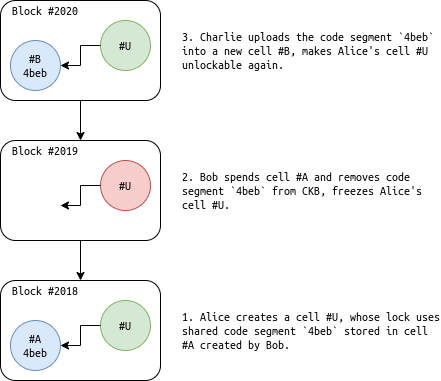
Figure 3. Recover from dependency kill.
Actually we can exploit this intentionally to achieve “use-then-deploy”. Suppose you want to use a new customized lock script (a smart contract) to protect your cells. Rather than the usual deploy-then-use flow, you can use it without deploy. Just put the code hash of your new lock script (the implementation) in cell locks (the usage), then those cells are guarded by the new lock, effective immediately.
The deployment of the actual lock script code can be delayed until the moment you want to unlock those cells. To unlock, first, you deploy the script code on-chain, then send another transaction to unlock those cells as usual. After cells are unlocked you can delete the deployed code and claim occupied CKBytes back to reduce unnecessary storage cost. An extra benefit of use-then-deploy is better privacy - no one knows what’s the logic of this new lock is before you unlock it.
Evolve CKB
Now you understand the similarity between CKB and Git and the benefits. A more interesting question is if CKB is a git repository can we use CKB to manage the code of CKB?
Yes! That’s why some CKB core functions like transaction signature verification and Nervos DAO are implemented as a smart contract. Take transaction signature verification for example - it is a core function of almost every blockchain and hardcoded in the native language (e.g. written in C in Bitcoin, Go in go-ethereum). To upgrade the blockchain a new software version must be distributed and deployed on majority nodes (soft-/hard-fork), which requires tremendous coordination effort. For CKB, the transaction signature verification can upgrade like other smart contracts, by deploying a new version on-chain. That gives CKB the same long-term upgradability proposed by Tezos.
We can do even better. On CKB each user holds his/her own data so a contract is more like a 2-party agreement between the user and CKB and individuals can make independent choices. If you use a contract by its code hash, it means “I agree to this specific version of this contract”. You don’t need to worry that the developers upgrade the contract code someday, as the code hash of new contract will be different and your lock/type will still refer to the old one instead of the new one. After a new version is deployed, it coexists with old versions in the system. If you use a system contract by its code hash, the new version will not affect you, and you can decide independently whether to upgrade or not. If the answer is yes you can update all cells to use the new version. Otherwise, just do nothing and stay with the old version.
This is a friendly guarantee to holders who may not be online frequently, as they can be assured the contract attached to their cells at creation time will never be changed. Your assets will be always locked in the way you specified when you lock it. That’s the ultimate guarantee for SoV users and why CKB assets are different from assets on other blockchains. It’s the same guarantee Bitcoin provides to holders by following a soft-fork only approach. The only downside is you bear the “too-late” risk when there’s a security upgrade. So for convenience, some people may still prefer to always stay with the latest version because they trust the dev team and don’t bother with contract review and manual upgrade, in which case they use the type id to reference contracts. Roughly speaking type id is like HEAD in Git, an updatable reference always points to the current version. By providing both options - reference by code hash and reference by type id - the right to choose appropriate upgrade strategy is given back to users. It’s always good to have options. We can have different choices, no one would be coerced to upgrade.
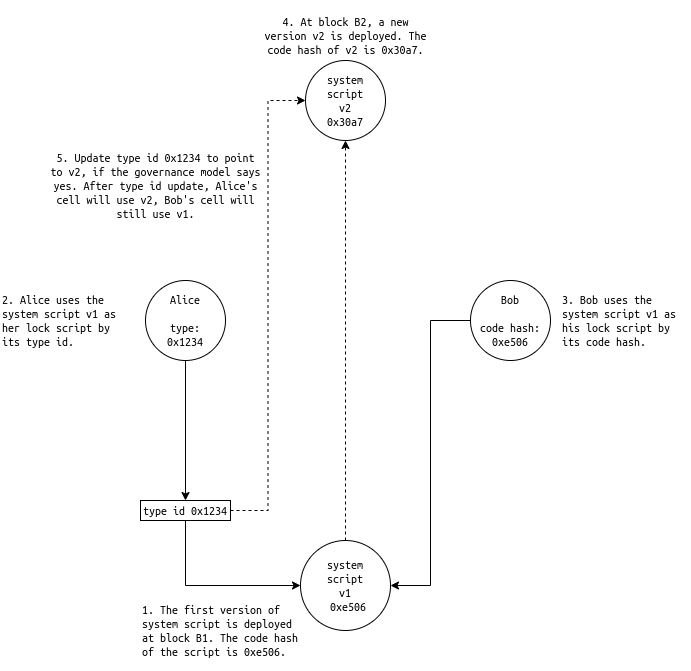
Figure 4. System script upgrade.
In the long term, CKB will be more and more abstract and modular, more core functions will be extracted and implemented in the on-chain smart contracts. In its complete form, we should be able to upgrade CKB without soft-/hard-forks. A missing piece to that is how we, the community, decide to upgrade a system contract or not, or what’s CKB’s governance model? More accurately, how we decide to upgrade the type id of a system contract. Today CKB uses the same off-chain governance model as Bitcoin and we still rely on soft-/hard-forks. To enable a new version of system script for people using its type id reference, a hard-fork is required to update the type id reference to point to the new version, because the code cell is locked by an unlockable lock (check its code hash). It is an intentional choice not to use a multi-signature lock controlled by the core team because the upgrade of system script should follow a governance decision made by the community.
As we stated in position paper, although there’re many interesting proposals we haven’t seen a viable governance model yet. Once we figured out the right governance model, the unlockable lock can be replaced with a “governance lock” that allows the system smart contracts to be upgraded with community consent, e.g. the result of votes. Before that, we’ll stick with the imperfect off-chain governance model for a while, but the backbone for CKB governance and evolution is already there.