RFC: Multi-Token Extensible NFT (Draft Spec)
Introduction
This is an alternate specification for NFTs on Nervos CKB, based off the original draft specification by Tannr Allard and taking inspiration from the ERC721, ERC998, and ERC1155 Ethereum standards.
A Non Fungible Token (NFT) is a token with unique qualities which may not be interchangeable or have equal value to other tokens within the same token class. Common uses include includes digital collectibles, video game items, and tokenized physical assets such as fine art and real estate.
The original NFT standard was created on Ethereum using ERC721, which was originally developed for the CryptoKitties game. However, it was quickly realized that the standard, while being perfectly suited for CryptoKitties, was inefficient or inadequate for the growing number of NFT use cases. ERC1155 was created a few months later to address these use cases.
This standard more closely follows ERC1155, of which the functionality encompasses both the ERC721 standard that the original draft specification is based on, and the ERC20 token standard that the SUDT standard is based on.
Key Differences and Motivations
The largest differentiators from the original draft specification are as follows:
Quantity Field
A quantity field has been included similar to ERC1155. This allows the token to function as a non-fungible token with fungible qualities. This effectively adds SUDT functionality within an NFT, and allows for more flexible interoperability with token standards on external chains.
This makes the standard suitable for more common use cases such as video game items, where a user can own more than one of a specific item. This will save a considerable amount of state space, meaning that ownership of assets will require far fewer CKBytes for a large number of similar items.
Dynamic Loading of Token Logic
Developer defined token logic is implemented using dynamic loading of deps instead of being implemented in the lock script. This allows NFTs to include custom functionality without having to rely on specific custom lock scripts.
This improves interoperability of NFTs between token platforms because it allows any lock script to be used. This is highly desirable because any platform that requires a custom lock, such as an NFT auction platform, would be incompatible otherwise.
Wallets will also benefit from this since it reduces the number of well-known lock scripts which will be included in the “white list” of safe scripts with known behavior. When new functionality introduced to a token it will not require the developer to inform the wallet of a new lock script definition.
Specification
This specification details the data structure and intended usage for an NFT. The functionality that must be present in any implementation is described including the rationale behind it.
Cell Structure
This basic cell structure of an NFT:
data:
instance_id: * (32 bytes)
quantity: u128 (16 bytes)
token_logic: code_hash (32 bytes)
custom: *
lock: <user_lock>
type:
code_hash: NFT Code Hash (32 bytes)
hash_type: code
args: <governance_lock_hash>, *
The data field of the cell includes the following:
- instance_id: The first 32 bytes represent the Instance ID. This identifier defines a token instance. These 32 bytes are a unique hash that is created when the cell is generated. The id must always be exactly 32 bytes in length.
- quantity: The next 16 bytes are a u128 representing the quantity of the token instance in the cell. The quantity must always be exactly 16 bytes in length. This field is optional and can be omitted if it is unused. If quantity is not used by the developer but the field is present, it should be set to a default value of 1.
- token_logic: The next 32 bytes represent the code hash of the token logic to be utilized. This hash must match the data hash of a cell dependency that contains the code which will be executed. This code contains any logic put in place by the developer to manage the token. The token logic field must always be exactly 32 bytes in length, but can be omitted if unused. If token logic is not used by the developer but the field is present, it should be set to a special value consisting of all zeros. The quantity field must be present in order for the token logic field to be used.
- custom: Additional data can be stored beyond the first 80 bytes. This data is defined by the developer, and it’s usage is optional. The quantity field and token_logic fields must be present in order for the custom field to be used.
The user_lock can be any lock script. This specification does place any restriction on the lock which is used.
The governance_lock_hash is a 32 byte hash that defines the lock script hash of the owner of the token which has administrative privileges.
A unique type script, which is comprised of a code hash, hash type, governance lock hash, and any additional args, is what defines a token class. A token class is dictated by the type script, which in turn includes the governance lock hash. Therefore, a token class is inherently connected to a specific lock script, which may be a single user, multiple users, or another script.
Generation
The generation model allows the owner the ability to mint unlimited new token instances within the same token class. The Instance ID assigned to each new token is generated using the seed cell design pattern, which means it is assigned randomly and is guaranteed to be globally unique. The quantity of tokens in a new token instance is defined at the time of creation and cannot be increased after generation.
The Instance ID is determined as follows:
For any new token instance being created, the Instance ID is a hash of the
outpoint of the first input, combined with the output index of the token
instance cell being created.
hash(seed_cell.tx_hash, seed_cell.index, instance_output_index)
By including the output index of the token instance, multiple instances can be created in a single transaction, and each one is guaranteed to have a globally unique Instance ID.
Example for generating two token instances in a single transaction:
inputs:
[Seed Cell]
data: <*>
lock: <governance_lock>
type: <*>
outputs:
[NFT Cell]
data:
<instance_id: hash(seed_cell.tx_hash, seed_cell.index, 0)>
<quantity>
<token_logic_hash>
<custom>
lock: <*>
type:
code_hash: NFT Code Hash (32 bytes)
hash_type: code
args: <governance_lock_hash>, *
[NFT Cell]
data:
<instance_id: hash(seed_cell.tx_hash, seed_cell.index, 1)>
<quantity>
<token_logic_hash>
<custom>
lock: <*>
type:
code_hash: NFT Code Hash (32 bytes)
hash_type: code
args: <governance_lock_hash>, *
Constraints
- Only the owner of a token class can mint new instances.
hash(input[i].lock) == governor_lock_script_hash - The Instance ID of a cell must be unique and based on the provided seed cell.
hash(seed_cell.tx_hash, seed_cell.index, output.index) == cell.instance_id - If the quantity field is used, it must be 16 bytes in length (u128). This it enforced by the constraint:
if data.length > 32: asset data.length >= 48 - If the token logic field is used, it must be 32 bytes in length. This it enforced by the constraint:
if data.length > 48: assert data.length >= 80 - If the token logic field is used, and is not zero filled, then the token logic hash must be a valid cell dep.
cell_dep[i].data_hash == token_logic_hash
Transfer / Burn
If owner mode is not detected in a transaction, then the transaction is assumed to be a transfer or a burn. A more restrictive set of constraints then applies, which allows modifications to the lock script and quantity field only.
Example for Alice transferring three of her ten tokens to Bob:
inputs:
[NFT Cell]
data:
<instance_id: ABCD>
<quantity: 10>
<token_logic: None>
<custom: None>
lock: <Alice>
type: <token_class: XYZ>
outputs:
[NFT Cell]
data:
<instance_id: ABCD>
<quantity: 7>
<token_logic: None>
<custom: None>
lock: <Alice>
type: <token_class: XYZ>
[NFT Cell]
data:
<instance_id: ABCD>
<quantity: 3>
<token_logic: None>
<custom: None>
lock: <Bob>
type: <token_class: XYZ>
Constraints
- Token instances can only be created from existing instances.
token_instance_output[i].instance_id == token_instance_input[i].instance_id - The token instances quantity in the outputs must be less than or equal to that in the inputs. If no quantity was present, the quantity is assumed to be 1.
sum(token_instance_output[..].quantity) <= sum(token_instance_input[..].quantity) - Token instances must not change the token_logic field.
token_instance_output[i].token_logic_hash == token_instance_input[i].token_logic_hash
Note: There is no constraint for the custom data in a cell, which is all data beyond the first 80 bytes. Any developer rules for the handling of this data should be included in the token logic script.
Update (Owner Mode)
When a transaction is created by the owner, execution will allow for additional changes to be made to the cell data that are not allowed in a transfer operation. Specifically, the token_logic field can be freely updated, and any custom data stored beyond the initial 80 bytes may also be modified freely.
Example for an update operation from the owner, Alice, who transfers three of her 10 tokens to Bob, and updates the token_logic and custom data:
inputs:
[Cell]
data: None
lock: <Alice>
type: None
[NFT Cell]
data:
<instance_id: ABCD>
<quantity: 10>
<token_logic: EDFG>
<custom: 555>
lock: <Alice>
type: <token_class: XYZ owner: Alice>
outputs:
[NFT Cell]
data:
<instance_id: ABCD>
<quantity: 7>
<token_logic: EDFG>
<custom: 222>
lock: <Alice>
type: <token_class: XYZ owner: Alice>
[NFT Cell]
data:
<instance_id: ABCD>
<quantity: 3>
<token_logic: HIJK>
<custom: 333>
lock: <Bob>
type: <token_class: XYZ owner: Alice>
Constraints
- Token instances can only be created from existing instances.
token_instance_output[i].instance_id == token_instance_input[i].instance_id - The token instances quantity in the outputs must be less than or equal to that in the inputs. If no quantity was present, the quantity is assumed to be 1.
sum(token_instance_output[..].quantity) <= sum(token_instance_input[..].quantity)
Token Logic Execution
The Token Logic Script is executed under these specific conditions:
- The NFT Cell Data contains a Token Logic value.
- The Token Logic code hash value is not zero filled, which would indicate the absence of a script.
- The Script is executing a transfer or burn operation.
- Owner Mode was not detected.
Token Logic is not executed during a generation or update operations since this would complicate the logic needed, and would complicate administrative actions on the NFT instance.
The Token Logic field should be set to a 32-byte Blake2b code hash of a Token Logic script that is compiled as a C Shared Library (cdylib). An easy way to obtain this hash is to use ckb-cli on the compiled binary:
ckb-cli util blake2b —binary-path ./build/release/token-logic.so
The binary should be added to the blockchain in a cell, and the outpoint of that cell can be included as a cell dep in a transaction where the NFT requires that specific Token Logic script.
The Token Logic script should follow the basic c-sharedlib template conventions from Capsule. At present time, Token Logic scripts must be written in C due to the lack of support for cdylib targets for RISC-V in the Rust compiler. Once support is added then we will be able to fully support Token Logic scripts written in Rust.
The Token Logic script shared lib requires a single external function which serves as the entry point for execution. This function takes a byte array containing the Token Logic code hash of the executing script itself.
// Rust Definition
fn(token_logic_code_hash: &[u8; 32]) -> i32
// C Definition
int32_t token_logic(const char* token_logic_code_hash)
The token_logic_code_hash value is included because it is necessary for proper NFT validation. Under common conditions, only those with a Token Logic value that matches the token_logic_code_hash should be processed during Token Logic script execution. If a different Token Logic value is present, then that cell should be excluded from validation since it is subject to validation by a different Token Logic script. However, this guideline may not apply for complex interactions between NFT instance types.
Script Logic Flowchart
This flowchart outlines the basic logical operation of the NFT instance.
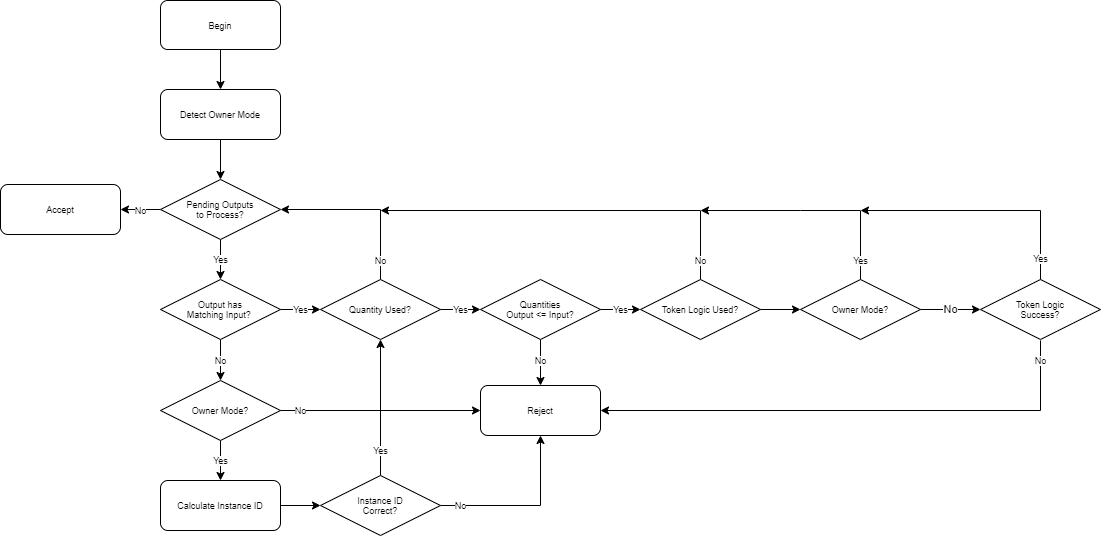
Considerations
Token Metadata
Similar to the SUDT standard, no metadata exists within the cells themselves. It would not make sense to include this data in every cell because this would needlessly require extra capacity. On-chain metadata should exist within a single cell that can be located easily by off-chain applications. The standard for how this metadata should be handled is not included because it is beyond the scope of this document.
Backwards Compatibility
This standard is partially backwards compatible with the original draft standard. If a new token instance was minted, with only the Instance ID present, omitting the quantity, token_logic, and custom fields, it would be functionally identical to the original draft standard. If any data exists beyond the Instance ID (32 bytes), then the constraints that apply are different.
Instance ID and Quantity Restrictions
This standard places restrictions on control over the Instance ID and Quantity values that cannot be overcome by the owner of the token class.
The SUDT standard allows the owner to mint an unlimited quantity of tokens at any time. Similarly, this standard allows the unlimited minting of new token instances at any time. However, unlike SUDT, the quantity of any token instance is fixed at the time it is minted and cannot be increased later.
In order to ensure that an Instance ID is unique, its creation uses the seed cell pattern. This effectively takes control of the Instance ID away from the owner. The owner controls when a token instance is created, but they cannot control what that Instance ID is. If quantity was left completely unrestricted, then this is effectively nullifying the aforementioned pattern. By keeping both the the Instance ID and quantity limited the standard is guaranteeing that a token instance is unique and unforgeable, even by the owner of the token class.
A real world example of why this trait is desirable would be collectable game cards such as Magic The Gathering. First editions of certain rare cards are extremely valuable to collectors. However, counterfeit prints of these rare cards exist, as do reprints by the original issuer. Restricting the Instance ID and quantity eliminates any possibility of malicious counterfeiting, and ensures that a later reprint by the issuer cannot be mistaken for the original printing.
Usage Examples
Below are some common NFT usages with examples of how it would be implemented using this standard.
Topps Garbage Pail Kids
Topps recently released the Garbage Pail Kids, trading cards popular in the 80’s, as NFTs on the WAX blockchain. These are basic trading cards without any additional functionality, which makes them very easy to implement using this standard.
The Dapp would mint a unique token instance for each unique card. No token logic or custom data would be required. The quantity field would be highly beneficial because it would allow a user to hold multiple cards of the same instance in a single cell. The associated metadata and image data would be held on Topps servers, which match against a particular Instance ID.

CryptoKitties
A Dapp like CryptoKitties will use custom token logic script to handle breeding actions between two NFT token instances. In this case, the “DNA” of the kitties is stored in the custom data area (beyond the first 80 bytes). The custom token logic script provided by the developer will ensure that it cannot be modified directly, and can only be updated according to specific rules during a breed transaction.
A new token instance can only be created by the Dapp owner, which means that the creation of a new kitty must obtain an Instance ID from the owner if a third kitty is to be created. This can easily be accomplished by having the Dapp provide empty egg instances which must be combined with two kitties in order to breed a third kitty. Here instance ABC and DEF combine their DNA within the GHI instance. The egg instances can be minted in bulk and distributed using an on-chain script, meaning that the breeding process can be done on-chain without the need for centralization.
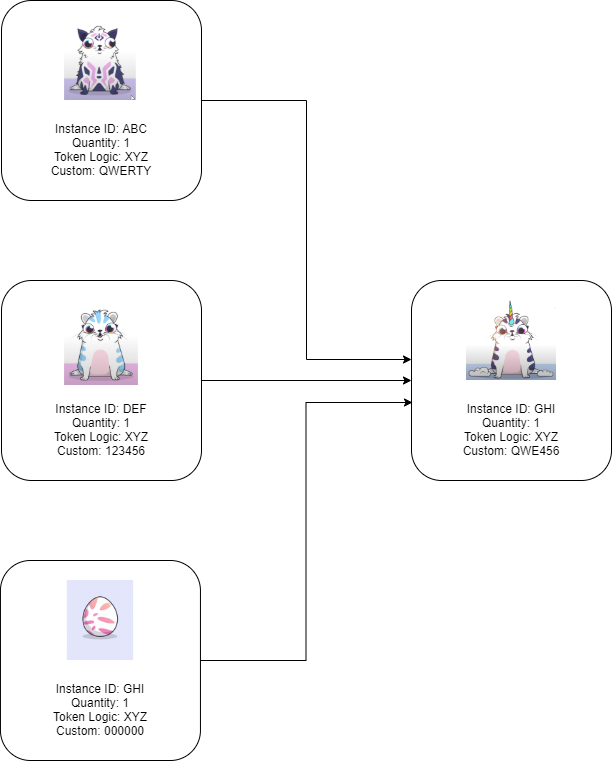
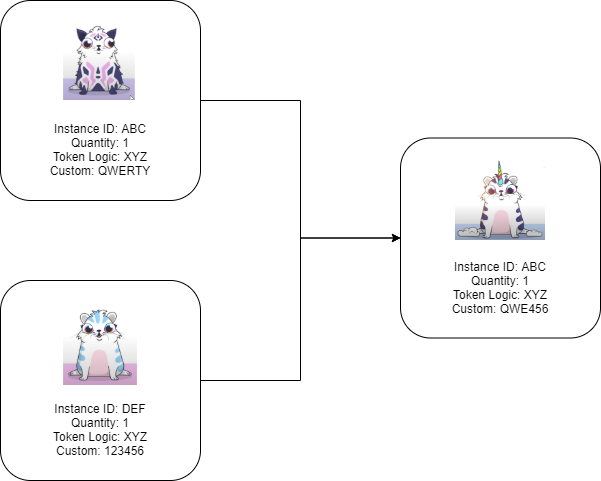
Another slightly different variant on the game could consume the two original kitties to produce a third. This would modify the game dynamic since it would mean a kitty would disappear after breeding, but this may be desirable if it was a game was instead CryptoSpiders, where death after breeding is expected.
In this case, instance ABC is reused, while instance DEF is consumed. The kitty “DNA” is combined in the resulting cell according to the rules provided in the token logic script.
Resident Evil (Guns and Ammo)
If Capcom was to release a Resident Evil with NFT based in-game items, common actions like reloading ammo can be accomplished on-chain without centralized Dapp logic.
In this case, a user owns a weapon represented by instance DEF, and owns 10 ammunition rounds represented by instance ABC. Token logic script RTY would allow the weapons ammo counter to be updated in a transaction where ammo is burned. The 10 ammo are burned in this transaction, which allows the ammo counter in the weapon to be updated from 0 to 10, reloading the weapon.

Reference Implementation
The reference implementation is written in Rust using the Capsule Framework, and can be found on GitHub. This specification is still considered a draft and the code is not production ready .