本篇文章转载自我的个人博客[研究] 可验证延迟函数(VDF)(一)一文搞懂 VDF。
转载版本:2019-06-09T22:00:00Z 更新
自从以太坊将可验证延迟函数(Verifiable Delay Function, VDF) 列入研究计划并打算在以太坊 2.0 使用之后,VDF 得到了广泛的关注。VDF 这个概念最初由斯坦福大学密码学教授 Dan Boneh 等人在其论文 Verifiable Delay Function 中给出。该篇文章于 2018 年发表在密码学顶级会议之一的 CRYPTO 上。
目前网络上有一些英文和中文的文章介绍了 VDF 的概念和原理,但是它们要么无法给出全面直观的解释,要么只是粗浅地谈论应用。本文试图通过浅显的语言和具体的例子来让对密码学和群论不够了解的读者能够全面而直观地理解它的定义和原理。同时,本文还给出了它的可能的应用场景以及目前的研究和应用状况。
简介
VDF 是一类数学函数,能够使得该函数的计算需要至少一段已知的时间,即使是在同时使用少量 CPU 进行并行计算的情况下(这与比特币的 Proof-of-Work (PoW) 不同,后文会详细解释)。VDF 通常会接受一个输入以及一些参数(安全参数、时间参数等),输出一个结果以及相应的证明(可以为空,如果结果能够自带证明)。验证者会依据输入、参数、输出以及结果来判断 VDF 的结果是否正确。
对于未精心设计过的算法,并行计算有可能极大地缩减其计算时间。以比特币的挖矿算法为例,设 0 \leqslant \mathtt{nonce} \leqslant 2^{32} -1 ,如果只有一个运算单元,那么可能需要耗费多达 2^{32} 次 SHA-256 计算的时间。如果有两个运算单元,就可以将任务对半分摊,让他们并行地计算哈希值。最多只需要耗费 2^{31} 次 SHA-256 计算的时间。
同时满足以下性质:
- VDF 的结果的检验应当是非常有效率的。
- 唯一性(Uniqueness):对于任意一个 VDF 的输入,应当有唯一的输出结果能够通过检验。也就是说,不存在两个不同的输出,他们有相同的输入。如果输出结果包含“结果”和关于结果的“证明”两部分,那么证明部分可以不具有唯一性,但需要保证“验证者因为证明而验证通过,但是输出结果却不是正确的结果”这件事发生的概率小到可以忽略不计。
- 串行性(Sequentiality):攻击者即使能够提前计算很长时间(但不是任意长的时间),并且拥有很多并行处理器(但不是任意多的处理器),利用各种计算方法(确定地计算或是连蒙带猜),能够以少于 t 的时间计算出 VDF 结果的概率可以小到忽略不计(并不是 0,因为也许攻击者真的就运气好到猜中了呢?)。
VDF 能够抵抗并行计算加速,这意味着为了计算 VDF,应当完成一系列串行才能完成的任务,后一个任务必须依赖于前一个任务。这时,对哈希函数有所了解的读者可能会想到一种方案:连续将一个输入哈希 t 次。这样的方案的确是无法通过并行算法显著地加速的,但是这样得到的结果,其验证将会非常没有效率:验证者需要重复哈希 t 次的计算,即使保留一些中间结果,验证的工作量和计算的工作量也是常数级别的差距。从这个例子我们可以看出,在这样的定义下,可验证延迟函数的构造并没有想象中的那么简单。
事实上,对于上面并不严谨的定义,去掉任何一个性质都会导致我们能够非常轻易地构造出可验证延迟函数:
- 如果不要求验证结果是高效的,也就是说没有显著地比计算结果更快,那么我们可以通过刚才提到的连续哈希的方案进行构造。
- 如果我们不需要它保证唯一性,那么早在 2013 年 Mahmoody 等人的工作 Publicly Verifiable Proofs of Sequential Work 就已经实现了这一点。
- 如果它不保证串行性,那么显然构造方法就更多了。
与 PoW 的区别
或许有读者会感觉 VDF 和 PoW 是一类东西,实际上,虽然他们计算起来都不是很容易,但是他们之间有很多关键的区别。
- PoW 不抵抗并行计算加速而 VDF 抵抗。实际上,PoW 不抵抗并行计算加速是符合中本聪的“一 CPU 一票”的设想的,而抗并行加速的性质只会与这个目的背道而驰。VDF 会使得多 CPU 的计算者和单 CPU 的计算者相比几乎没有什么优势。
- 对于固定的难度设定 d ,PoW 可以有很多合法的解,这也是保证 PoW 共识网络拥有稳定的吞吐量以及刺激矿工进行竞争的前提。而对于给定输入 x ,VDF 拥有唯一的输出(这也是为什么它被称作函数)。
上述两条性质决定了 PoW 直接作为随机数的来源是有缺陷的,同时,VDF 也无法直接替代 PoW。但是这并不能说明 VDF 不可以被用到共识协议里,这一点会在下一个章节详谈。
用途
上一章节我们介绍了 VDF 是什么,以及它具有怎样的性质,这一章节我们关注它的用途。
增强公共可验证随机数的安全性
区块链上的随机数一直是一个热门话题。无论是在一些权益证明(Proof-of-Stake, PoS)共识协议的设计里,还是在智能合约平台,譬如 Ethereum 和 EOS,上一些非常火爆的游戏类应用,随机数都占据了核心的地位。同时,很多这些应用中,实际设计的随机数获取方案还非常不成熟,以至经常会有应用因为不安全的随机数而被黑客攻击的新闻出现。
VDF 对于一些从公共来源获取随机数的方法非常有用。比如从股票市场或者是从 PoW 区块链上获取。这些随机源拥有足够的随机性(更严格地讲,是最小熵)。但是高频交易者可以影响股价,同时,PoW 区块链的矿工也可以通过不广播自己挖出的区块来降低自己不想要的随机数结果的出现概率。但是这样的攻击方式成立的前提条件是攻击者有时间在其他诚实参与者之前预测出随机数结果。VDF 恰好能阻止这一点。如果将 VDF 的时间参数 t 设置到足够长(比如 10 个块的间隔),将最新的区块头作为输入扔进 VDF 中,输出作为随机数结果。那么攻击者只能在 10 个块之后才能知道随机数的结果是什么,那个时候想要再改变结果已经很难了(需要 fork 10 个区块)。
此外,VDF 也可以增强一些多方参与的随机数方案。比如 Commit-and-Reveal 方案中,攻击者可以拖到 Reveal 阶段的最后再决定是否揭示自己的承诺。如果我们去掉 Commit 阶段,并且协议的最后整合所有人的输入之后不直接作为随机数结果,而是放入 VDF 中,并且将 VDF 的时间参数 t 设置到足够长(晚于最后提交期限),那么即使是最后一刻提交的人也无法知道随机数的结果,操纵结果也就无从谈起。与之相比较,其他的多方参与方案通常最多容忍小于一半的恶意节点,并且交互的开销要比上述方案更大。
解决 Nothing-at-stake Attack
正如上一节所述,VDF 可以用于增强随机数生成方案的安全性,因此,在一些使用了随机数来选取 Leader 的共识协议中也可以使用 VDF 在增强其安全性。一些节约能源的共识协议,例如 PoS,空间证明(Proof-of-Space)以及存储证明(Proof-of-Storage),为了防止 Nothing-at-stake attack,需要使用随机选举每隔一段时间选举出一个 Leader。这些协议使用的随机数方案大多只在诚实参与者占据大多数时保持安全。利用 VDF 可以降低这样的限制到至少存在一个诚实参与者。
Nothing-at-stake Attack
PoS 区块链发生分叉时,共识参与者为了自己的利益会选择在不同的分叉链上同时进行抵押资产参与出块,这样分叉链有可能会一直存在并且分叉越来越多,严重危害系统的一致性,这样的攻击被叫做 Nothing-at-stake attack。在 PoW 链上进行这样的攻击需要分散算力,因此这样的攻击只适用于“节约能源”的共识协议。
除了随机选举之外,还有一种叫做 Proofs of Space and Time 的方案可以防止这种攻击。实际上该方案模拟了 PoW 的挖矿过程:挖出区块的时间是不确定的,并且每个矿工都在互相竞争成为最早挖出区块的人。不一样的地方在于,模拟挖矿过程实际上并不需要消耗大量的并行计算资源(Proof-of-Time),只有在进入挖矿时有一定的门槛(Proof-of-Space)。具体来讲,整个挖矿过程按照时间顺序被分成不同的区间,每一个区间都有一个公共随机的挑战 c (举个例子,可以是前一个区间挖出的块的哈希值)。假设某个矿工拥有的空间单位为 N ,他需要生成一个证明 \pi 来证明他拥有这 N 单位的空间,并且专门用于该区块链的挖矿,这一点由 Proof-of-Space 保证。矿工的目标为找到最小的 \tau = H(c, \pi, i), 1 \leqslant i \leqslant N ,然后将 c 作为输入计算一个 VDF(事实上是增量 VDF),该 VDF 的时间参数与 \tau 正相关。这样的设计中,拥有空间越多的矿工找到更小的 \tau 的可能性更大,同时,VDF 保证了一段时间的流逝,使矿工大量分叉需要消耗大量的时间。
减轻 Long-range Attack
几乎所有的 PoS 方案都面临 Long-range attack 的问题。目前 PoS 协议依赖于外部的时间戳服务来帮助他们解决这个问题——只要能判断哪一条链更老,就能阻止这样的攻击发生。VDF 能够帮助 PoS 解决这样的问题。VDF 相当于一种时间流逝的证明,对于给定的 VDF,该 VDF 至少需要多久才能得出结果是一个公共知识。因此,只需要在 PoS 链上包含 VDF 的输入与输出即可证明给定区块的历史。
Long-range Attack
在 PoS 协议中,任意时刻都有一组权益相关者拥有按照权益多少分配的投票权。PoS 假设大多数权益相关者并没有理由对系统造成破坏,因为这样反而会损害自己的权益。但是如果这些权益相关者在某一个时间点出售了自己的权益,这样的激励对他们来讲是无效的。这些已经出售了自己权益的曾经的权益相关者仍然可以在曾经某一个时间点轻易对(那时他们占据大多数权益) PoS 链分叉达到原有链的的长度,从中攫取额外的利益,这样的攻击被称作 Long-range attack。它在 PoW 上不太可能发生,因为对于 PoW 来讲,无论从哪一个时间点进行分叉,都必须要付出相应的算力才能追上原有的链,想要分叉的区块越多,付出的算力也就越多。
但是必须要指出的是,这样的方法并不是完美的,因为 VDF 仍然是可以被特殊硬件加速的(尽管是常数级的)。如果攻击者获得了诚实节点 10 倍的计算速度,那么这样的加速对于使用 VDF 作证明的 PoS 链是不可接受的(攻击者可以在 10 年之后伪造出 1 年以前的区块)。
10 倍的加速对于随机数生成的场景无所谓,因为该场景下,不需要保证“攻击者算得没有诚实节点快”,只需要保证攻击者无法在某个时间点(随机数来源再也无法更改的时间点,例如股市闭市)之前无法计算出结果即可。从而在随机数生成的场景,我们可以选取一个足够长的时间参数,使得攻击者即使加速也无法操纵随机数。
副本证明(Proof of Replication)
副本证明所需要解决的问题是,服务器如何向客户端证明自己在某一专门的存储介质上存储了指定的数据,即使这样的数据是可以从别的存储来源轻易获得的。注意副本证明是为了证明服务器拥有一份数据的副本,而不是证明它有这样的数据。举个例子,云存储服务提供商声称自己为客户的数据做了额外的两份冗余备份来保证用户数据的 availability,因此客户需要为这样的冗余备份交更多的钱。但是怎么证明云服务提供商有一共三份副本而不是两份或者只有一份呢?这就需要用到副本证明。一种思路是利用在时间上不对称的编码方案(也就是编码很慢,但是解码很快),VDF 可以做到这一点(事实上是可解码 VDF)。身份为 \mathit{id} 的服务器首先将文件分成 b-bit 大小的文件块 B_i, 1 \leqslant i \leqslant n ,然后计算 B_i \oplus H(\mathit{id} || i) 并将结果作为输入放进 VDF 计算得到 y_i, 1 \leqslant i \leqslant n ,其中 H 是输出长度为 b -bit 的防碰撞哈希函数。服务器存储所有的 y_i ,客户端不断随机挑选 i 进行轮询要求服务器返回 y_i ,服务器在规定时间内需要响应给客户端相应的结果,而客户端可以在很短的时间内通过解码 y_i 得到 B_i 完成验证。如果服务器没有存储 y_i ,那么想要正确响应客户端必须计算 y_i ,然而这样的计算无法在规定的时间内完成。服务器也可以只存储一部分 y_i (比例为 \rho ),由于客户端是随机轮询,每一次服务器成功欺骗客户端的概率为 \rho 。只要客户端重复 k 次这样的轮询,就可以将服务器欺骗成功的概率降到 \rho^k 。需要补充的一点是,服务器可以不存储 B_i ,由于 y_i 解码很快,即使只存储 y_i 也不会太影响性能。
基本原理
既然 VDF 是一个函数,那么它就必然具有这样的形式: f : \mathcal{X} \to \mathcal{Y} 。为了实现前文所述的功能,即“抵抗并行计算的延迟”以及“可验证的结果”,VDF 中必然包含一个用于计算结果的算法以及一个用于验证结果的算法。同时,这样的密码学工具通常还包含一个配置阶段,用来确定后续需要使用的参数。因此,VDF 被描述为三个算法的一个三元组 (\mathsf{Setup}, \mathsf{Eval}, \mathsf{Verify}) 。
每个算法的定义如下:
- \mathsf{Setup}(\lambda, t) \to \mathbf{pp}=(\mathsf{ek},\mathsf{vk}) 接受安全参数 \lambda 以及时间参数 t ,生成一个公共参数 \mathbf{pp} ,这个参数是所有人都可以看到的。公共参数 \mathbf{pp} 包含了一个用于计算的参数 \mathsf{ek} 和一个用于验证的参数 \mathsf{vk} 。
- \mathsf{Eval}(\mathsf{ek},x) \to (y,\pi) 接受计算参数 \mathsf{ek} 和输入 x \in \mathcal{X} ,计算出输出 y \in \mathcal{Y} 和证明 \pi
- \mathsf{Verify}(\mathsf{vk}, x, y, \pi) \to \{\mathit{accept}, \mathit{reject}\} 接受 \mathsf{vk} , x , y 以及 \pi ,输出 \mathit{accept} (验证通过)或者 \mathit{reject} (验证失败)。
如图 1 所示我们可以看到 VDF 通常的运行流程。
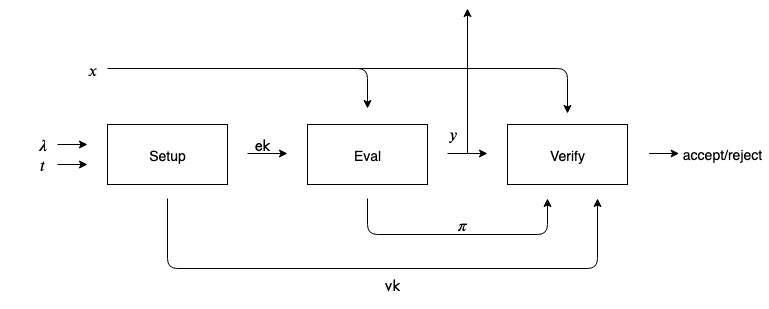
图 1:可验证延迟函数
以上几个算法有一些需要补充说明的地方:
- 关于 \mathsf{Setup}
- \mathsf{Setup} 的运行时间不能太久,它被安全参数 \lambda 所限制。
- \mathsf{Setup} 这个阶段通常会需要随机数作为参数以保证安全性,如果随机数是私下选择的,也就是不可公开的,那么这个阶段就会需要一个可被信任的一方来进行随机数的选择,称之为 trusted setup。相反,如果随机数可以是公共随机数,那么这个阶段就不需要这样的 trusted setup。显然,我们希望尽量避免 trusted setup。
- 关于 \mathsf{Eval}
- 证明 \pi 不是必须的,如果仅仅通过 y 就能验证的话。
- 在 y 的计算中,不允许有随机数的引入(为了保证唯一性),但是在 \pi 的生成过程中可以引入。
- 为了保证串行性, \mathsf{Eval} 在拥有不超过关于 t 的多项式对数(Poly-log) 个并行处理器时,运行时间必须为 t 。
- 为什么 \mathsf{Eval} 要允许一定程度的并行计算达到时间 t 呢?因为可能并没有构造能够完美地让并行和串行计算时间完全相同,所以我们需要容忍一定量的不太显著的并行加速。
- 关于 \mathsf{Verify}
- \mathsf{Verify} 中不引入随机数,也就是说,它是确定性算法。
- \mathsf{Verify} 的运行时间要比 t 小得多,具体来讲,他们在运行时间上拥有指数级别的差距(Exponential gap)。
基于上述定义,VDF 还有一些拥有特殊性质的变种:
- 可解码 VDF(Decodable VDF):如果对于一个 VDF 方案,存在一个算法对于任意 x \in \mathcal{X} 能够从 y \in \mathcal{Y} 反向计算出 x ,那么这个 VDF 就是可解码 VDF。在这样的情况下,证明 \pi 是不需要的。当然,一个平凡的构造是,将 \pi 放进 y 里面。
- 增量 VDF(Incremental VDF):如果在 \mathsf{Setup} 算法中,参数 t 没有被唯一确定,而是允许在 \mathsf{Eval} 的输出之一 \pi 中指定,这样的 VDF 被称作增量 VDF。一种效果类似的构造是,在 \mathsf{Setup} 中设定 t 为一个单位的时间,如果想要在计算阶段达到不同的延迟时间,例如 T = nt ,只需要串行 n 次 \mathsf{Eval} 即可。但是这样的构造会导致 n 倍的证明长度,增量 VDF 不会产生额外的证明。
- 陷门 VDF(Trapdoor VDF):如果某个 VDF 方案存在一个算法,使得知道某一秘密值 \mathsf{sk} 的人能够通过这个算法迅速由 \mathsf{Eval} 的输入得到 \mathsf{Eval} 的输出,那么这个 VDF 是陷门 VDF。更直观的理解是,陷门 VDF 有一个后门可以让人绕过延迟限制迅速算出结果。
- 弱 VDF(Weak VDF):如果我们放宽限制,允许“即使在 \mathsf{Eval} 中使用多项式(Polynomial) 个并行处理器才能在 t 时间算出结果”这样的情况出现,这样的 VDF 被称作弱 VDF。弱 VDF 在实际应用中会更加消耗诚实参与者的算力(因为相比 VDF 而言需要更多的并行处理器才能达到 t 时间)。但如果将 VDF 用于生成公共可验证的随机数,可以将计算任务交给一个诚实参与者,其他参与者等着验证。这时,这样的唯一计算者是可能拥有足够多的处理器的。
一种简单的构造方式
上文提到了使用连续的哈希操作是一种防止并行的计算加速的手段,但是这样的手段非常低效,不符合 VDF 的定义。我们希望能够找到一种验证更加迅速的防并行的构造方式。考虑这样的一个例子:
首先选择一个数 \lambda = 161 ,然后然后对于任意的输入 x ,我们执行下面的操作 t 次:
- 计算 k = x^2
- 取 k 除以 \lambda 的余数得到 l
- 令 k 取 l ,返回第一步,如果是最后一次操作,输出结果 y
假设我们的输入 x = 11 , t = 8 ,那么结果为 95 ,事实上,如果我们让 t 取不同的值,把结果都记录下来,可以得到下述表格
| t | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
|---|---|---|---|---|---|---|---|---|
| y | 121 | 151 | 100 | 18 | 2 | 4 | 16 | 95 |
更一般地讲,如果 a \equiv b \mod m 代表 a 和 b 分别除以 m 的余数相同的话,那么上述操作实际上就是计算
如果我们知道 \lambda 的因式分解,例如 161 = 7 \times 23 ,那么我们可以通过两次指数运算来快速计算出 y 的值。首先计算函数 \phi(161) = (7-1) \times (23-1) = 132 ,然后计算 2^t 除以 \phi(161) 的余数
然后计算 x^{124} 除以 \lambda 的余数
上述过程比起连续平方 8 次看似没有减轻多少工作量,但实际上当 t 和 \lambda 非常大( t \approx 2^{30} )时,远比连续平方快得多。一般地,函数 \phi(n) = \prod_{i=1}^r p_i^{k_i-1}(p_i-1) ,如果 n = p_1^{k_1}p_2^{k_2} \cdots p_r^{k_r} 。这个函数被称之为欧拉函数(Euler’s Totient Function)。上述例子可以一般化为
因此,如果没有任何人知道 \lambda 的因式分解,也就无法快速计算出 \phi(\lambda) ,从而只能重复 t 次平方操作使用
计算出 y 。
事实上,这个构造可以使用群论得到更加本质的解释。我们发现,由于模运算 y 的值是小于 \lambda 的,而所有小于 \lambda 且与 \lambda 互素的数一起组成了一个群(Group),这个群被称作整数模 \lambda 乘法群,记作 (\mathbb{Z}/\lambda\mathbb{Z})^* 。这个群的阶(Order),也就是元素个数就等于欧拉函数 \phi(\lambda) 的值。因此,关键问题落在了如何生成这样的知道阶的群。
目前主要有两种方法:
- 使用 RSA 群
- 使用虚二次域的类群(The class group of an imaginary quagratic number field)
RSA 群的生成与 RSA 加密算法类似,选取大素数 p 和 q ,其中 p=2m+1 , q=2n+1 且 m ,n 均为素数。令 N=pq ,则 (\mathbb{Z}/N\mathbb{Z})^* 即为所需群。然而一个很显然的问题是,这其中涉及到了 trusted setup,我们必须相信生成 N 的参与者不会泄露 p 和 q 。我们也可以使得群生成算法使用公共随机数来直接选取足够大的 N 使得因式分解 N 非常困难,但是这样的 N 需要非常大以至于这样的方法非常不现实。第二种方法解决了第一种方法的问题,但是由于第二种方法解释起来涉及概念较多,本篇文章不会涉及。同时,对于结果 y 的快速验证需要用到证明系统,有兴趣的读者可以参考 Boneh 的一篇综述。
研究与应用现状
学术界第一次正式提出 VDF 的概念是在 Boneh 的论文中,他在论文中给出了 VDF 的应用场景以及形式化的模型,安全分析和一般构造方法。之后出现了分别出现了两篇 VDF 的构造论文,分别是 Wesolowski 的 Efficient VDF 以及 Pietrzak 的 Simple VDF。两者都利用在不知道阶的群中连续做平方运算的方法来构造 VDF,不同的是,他们生成证明的构造有所区别。简单来讲,Wesolowski 的证明更短,验证更快;但是 Pietrzak 的构造中,生成证明的速度更快,同时证明系统依赖的安全假设更弱。2019 年 Feo 等人使用超奇异同源 (Supersingular Isogenies) 以及双线性对(Bilinear Pairings)构造 VDF。相比于 Wesolowski 和 Pietrzak 的工作,他们的构造本身就是非交互的,不需要经过转换,同时不需要证明 \pi 即可完成验证,但是他们的构造中 \mathsf{Setup} 耗费的时间更长,更为主要的是,目前还只能进行 trusted setup。
在应用领域,Chia Network 计划使用 VDF 来支持他们的 Proof-of-Space;以太坊研究团队也打算在以太坊 2.0 中引入 VDF,以期在以太坊 2.0 信标链中使用 RANDAO + VDF 随机选取出块人。最初以太坊计划使用 RANDAO + VDF 的方案。但由于以太坊 2.0 的计划瞬息万变,截至文章最后修改前,以太坊信标链计划将区块间隔限制到 6 秒,64 个区块为一个 epoch,因此一个 epoch 为 6.4 分钟,每一个 epoch 需要进行一次出块人切换,因此 VDF 的时间参数最少应设置为 6.4 分钟,但是目前以太坊计划将其设置为 102.4 分钟,目的是防止潜在的攻击者利用特殊硬件加速 VDF。