Hi @IrisNeko,
感谢你的积极推进~~
关于你提到的几个问题:
-
官方文档及 Repo 列表: 委员会已经在着手确认目前最新、最核心的官方文档链接,会尽快整理好提供给你。
-
历史数据快照: 很遗憾,委员会没有现成的打包数据集供你直接使用,初始数据的获取还是需要你通过 API 自行抓取。
请先按照你规划的方向继续推进,文档链接准备好后我们会第一时间同步给你。
Hi @IrisNeko,
感谢你的积极推进~~
关于你提到的几个问题:
官方文档及 Repo 列表: 委员会已经在着手确认目前最新、最核心的官方文档链接,会尽快整理好提供给你。
历史数据快照: 很遗憾,委员会没有现成的打包数据集供你直接使用,初始数据的获取还是需要你通过 API 自行抓取。
请先按照你规划的方向继续推进,文档链接准备好后我们会第一时间同步给你。
本周按照上周计划,围绕数据获取与数据库构建两条主线推进。完成了检索层双层数据库架构的落地实现、多路检索融合流程的工程化,以及 Nervos Talk 论坛爬虫的开发与接入。"数据获取 → 数据入库"最小链路已基本跑通,但受制于官方文档尚未整理完毕,暂未进行完整数据集的统一测试。
本周完成了"浅层索引 + 深层原件"双层存储模型的工程实现:
ArchiveStore(SQLAlchemy ORM)存储完整原文,字段涵盖 raw_text、raw_format、content_hash 等,支持去重和增量更新。DualLayerWriter:同步写入两层,content_hash(SHA-256)作为幂等键,重复入库不产生冗余记录。这一架构避免了为频繁变更的大库维护全量知识图谱,同时保留了随时通过锚点(anchor)拉取完整原文的能力。
在双层存储基础上,本周同步实现了四路检索融合管道:
query
├─ 1. 向量检索 (Qdrant) — 语义召回
├─ 2. BM25 检索 (rank_bm25) — 关键词/术语召回,支持中英文混合分词
├─ 3. 模糊匹配 (difflib) — 命名变体、缩写、轻微拼写差异
└─ 4. 精确匹配 (Qdrant 过滤) — 函数名、类名、帖子标题等硬锚点
↓
RRF 融合(Reciprocal Rank Fusion)
↓
Evidence(附带各路来源分数溯源)
MultiRetriever 统一管理四条路径,各路径可通过配置独立开关,RRF 结果的 payload 字段保留了每条路径的原始得分,便于后续诊断和调优。
针对 Nervos Talk(Discourse 论坛)开发了完整的爬虫模块:
/t/{id}.json、/t/{id}/posts.json),支持分页批量拉取。html_to_text 将 Discourse 返回的 cooked HTML 转换为干净纯文本,保留代码块标记。scripts/run_discourse_crawl.py CLI,支持单 topic 爬取、最新话题扫描、分类爬取等模式。数据获取 → 清洗 → 双层入库 → 多路检索的完整链路已通过集成测试验证(含对 https://talk.nervos.org 的真实 API 请求)。等待 Nervos 官方整理好最新文档后,再进行完整数据集的统一入库测试。
本周完成了从"数据库结构设计"到"可运行数据管道"的跨越。当前已经可以通过一条命令将论坛帖子完整地写入双层数据库,并通过多路融合检索取回结果。这为后续接入更多数据源(RFC 文档、GitHub 代码)以及 LangGraph 工作流调用真实检索打下了基础。
官方文档数据源尚未就绪,当前检索效果的验证仍依赖少量样本数据,尚未在完整语料下进行系统性的检索质量评估。BM25 索引目前为内存构建,进程重启后需重新加载;待数据量增长后需考虑持久化方案。
当前图引擎的主链路已成型,但检索节点仍使用 Mock 数据,下周重点将工作流与真实数据层打通:
RetrievalExecutor 节点中的 Mock 实现替换为真实的 MultiRetriever,使图引擎能够从 Qdrant + SQLite 双层库中召回实际证据。MemoryService 与图状态的联动,使 Agent 在多轮对话中能够读取用户历史记忆和频道上下文,丰富检索过滤条件。开始推进 Bot 接入层,以 Telegram 为首个接入平台,通过 MCP(Model Context Protocol)将 Telegram 消息通道封装为标准工具接口:
MCPTransportAdapter 抽象基础上,新增 TelegramTransportAdapter,将 Telegram 消息的接收与回复封装为图引擎可直接调用的工具接口。ResponseNormalizer,将图引擎输出的 FinalResponse 转换为 Telegram 支持的 Markdown 格式,处理长回复的分段发送逻辑。Following last week’s plan, this week’s progress was driven by two main tracks: data acquisition and database construction. We completed the implementation of the dual-layer database architecture for the retrieval layer, the engineering of the multi-way retrieval fusion pipeline, and the development and integration of the Nervos Talk forum crawler. The minimum viable pipeline of “data acquisition → data ingestion” is basically operational. However, because the official documentation has not yet been fully organized, we have temporarily paused unified testing on the complete dataset.
This week, we completed the engineering implementation of the “shallow index + deep original document” dual-layer storage model:
ArchiveStore (SQLAlchemy ORM) to store the complete original text. Fields include raw_text, raw_format, content_hash, etc., supporting deduplication and incremental updates.DualLayerWriter: Synchronously writes to both layers, using content_hash (SHA-256) as the idempotent key to prevent redundant records during repeated ingestions.This architecture avoids the need to maintain a full knowledge graph for a frequently changing large database, while preserving the ability to fetch the complete original text via anchors at any time.
Building upon the dual-layer storage, we simultaneously implemented a four-way retrieval fusion pipeline this week:
query
├─ 1. Vector Retrieval (Qdrant) — Semantic recall
├─ 2. BM25 Retrieval (rank_bm25) — Keyword/term recall, supports mixed English-Chinese tokenization
├─ 3. Fuzzy Matching (difflib) — Naming variants, abbreviations, minor spelling differences
└─ 4. Exact Match (Qdrant filter)— Hard anchors like function names, class names, post titles
↓
RRF Fusion (Reciprocal Rank Fusion)
↓
Evidence (includes score tracing from each source)
The MultiRetriever centrally manages these four paths, each of which can be toggled independently via configuration. The payload field of the RRF results retains the original scores from each path to facilitate subsequent diagnostics and tuning.
Developed a complete crawler module for Nervos Talk (a Discourse forum):
/t/{id}.json, /t/{id}/posts.json), supporting paginated batch fetching.html_to_text converts the cooked HTML returned by Discourse into clean plain text, preserving code block formatting.scripts/run_discourse_crawl.py CLI, supporting modes such as single-topic crawling, scanning for latest topics, and category-based crawling.The complete pipeline of “data acquisition → cleaning → dual-layer ingestion → multi-way retrieval” has been verified via integration testing (including actual API requests to https://talk.nervos.org). We are waiting for the official Nervos team to finalize the latest documentation before conducting a unified ingestion test on the complete dataset.
This week marks the leap from “database architecture design” to a “runnable data pipeline.” Currently, we can completely ingest forum posts into the dual-layer database and retrieve results via the multi-way fusion retrieval using a single command. This lays the groundwork for integrating more data sources (RFC documents, GitHub code) and allowing LangGraph workflows to call real retrieval mechanisms.
The official documentation data source is not yet ready. Verification of the current retrieval effectiveness still relies on a small amount of sample data, and a systematic retrieval quality assessment on a complete corpus has not yet been conducted. The BM25 index is currently built in memory and needs to be reloaded after process restarts; a persistence solution needs to be considered as the data volume grows.
The main pipeline of the graph engine has taken shape, but the retrieval nodes still use Mock data. Next week’s focus will be connecting the workflow with the real data layer:
RetrievalExecutor node with the real MultiRetriever, enabling the graph engine to recall actual evidence from the Qdrant + SQLite dual-layer database.MemoryService and the graph state, allowing the Agent to read the user’s historical memory and channel context in multi-turn dialogues, thereby enriching retrieval filter conditions.Begin advancing the Bot integration layer, starting with Telegram as the first platform. We will use MCP (Model Context Protocol) to encapsulate the Telegram messaging channel into standard tool interfaces:
MCPTransportAdapter abstraction by adding TelegramTransportAdapter, encapsulating the receiving and replying of Telegram messages into a tool interface directly callable by the graph engine.ResponseNormalizer to convert the FinalResponse outputted by the graph engine into the Markdown format supported by Telegram, handling the segmented sending logic for long replies.@xingtianchunyan 您好,请问这些最新最核心的文档官方链接,最晚什么时候能提供,我可以据此更好地安排开发进程。
Hi @IrisNeko ,
很开心看到你的最新进展,你的稳定发挥值得赞扬~~
以下是你可以用到的核心文档链接:
Nervos Network:Nervos Network · GitHub
Web5:web5fans · GitHub
DevRel:CKB DevRel · GitHub
RGB++ : RGB++ Protocol · GitHub
Fiber:GitHub - nervosnetwork/fiber: A scalable, privacy-by-default payment & swap network · GitHub
App5:appfi5 · GitHub
关于文档我想需要向你道声抱歉,耽误了一些时间,希望以上的核心文档足够你推进当前的工作。有拿不准的地方可以再跟我们确认。
祝好
行天
本周围绕“真实数据接入 + 真实模型回答”推进,重点完成了 GitHub 多源文档抓取与入库、检索库规模化构建,以及可直接运行的 Agent 端到端示例。当前系统已经能够在真实数据库中检索证据,并调用 glm-4.7 生成带引用的回答,形成“数据抓取 → 入库 → 检索 → 回答”的可用闭环。
README、docs/、guide/、*.md、*.rst 等),跳过明显非文档目录。1232 条(seen=1232, written=1232)。163 个 repo topic。data/sources/github_docs.jsonl,可用于复现和二次处理。archive.db)已写入对应记录。source/topic/type 过滤检索范围。glm-4.7,可基于检索证据生成引用化回答。pytest -m 'not integration'),确保新增能力未破坏既有链路。本周项目从“可演示的检索框架”升级为“可直接用于问答验证的工程化系统”。核心价值在于:
glm-4.7 + 引用)。TelegramTransportAdapter:对齐现有 MCP 接口,完成消息输入/输出适配。FinalResponse 转为 Telegram Markdown 并处理长消息分段。This week focused on real data integration + real model answering. We completed multi-source GitHub documentation crawling and ingestion, scaled retrieval database construction, and a runnable end-to-end Agent demo. The system now retrieves evidence from the real database and generates citation-grounded answers with glm-4.7, forming a practical pipeline from crawling to answering.
README, docs/, guide/, *.md, *.rst, etc.) and exclusion of non-doc directories.1232 documents ingested (seen=1232, written=1232)163 repository topicsdata/sources/github_docs.jsonl generated for reproducibility and reprocessingsource/topic/type.glm-4.7, producing evidence-grounded answers.pytest -m 'not integration'), confirming no breakage.The project has moved from a demo-oriented retrieval framework to a practical, testable QA system:
glm-4.7 citations.TelegramTransportAdapter aligned with existing MCP interfaces.因个人私事耽搁,本期(第四周)周报较原计划推迟一天发布,感谢理解。
本周聚焦把已有检索问答链路接到真实 Telegram 入口。目标是先实现“可收消息、可走图引擎、可回消息”的最小在线闭环,模型继续使用 glm-4.7。
Telegram 在线链路打通
已完成 Telegram update -> MessageEnvelope -> GraphState -> OutboundMessage -> sendMessage 的主流程接通。
Telegram runtime 可运行化
完成 polling 运行时与脚本,包含 getMe/getUpdates/sendMessage 封装、offset 持久化、allowed_chat_id、dry-run 等调试能力。
图引擎线上稳定性修复
修复依赖注入在图状态中的保留问题(如 _multi_retriever、_provider_registry),并对技术问答默认启用检索优先,减少“零证据直答”。
兼容与回退机制补齐
规划器产出不支持工具名时自动降级到 qdrant_search,避免空跑。
基础验证完成
已通过相关回归与 Telegram 实测,@NBCKB_Bot 可在线收发并返回有效回答。
missing_params 持久化、恢复与断言。ask_user 命中率,并据此迭代 Prompt 模板。This week focuses on connecting our existing retrieval-answer pipeline to a real Telegram entry point. The target is a minimal but usable online loop: receive message, run graph, send reply. Model remains glm-4.7.
End-to-end Telegram path is connected
Implemented Telegram update -> MessageEnvelope -> GraphState -> OutboundMessage -> sendMessage.
Runnable Telegram polling runtime
Added getMe/getUpdates/sendMessage wrappers, persisted update offset, allowed_chat_id, and dry-run controls.
Graph runtime stability fixes
Preserved injected dependencies in graph state (e.g., _multi_retriever, _provider_registry) and enforced retrieval-first behavior for technical QA.
Planner compatibility fallback
Normalized unsupported planner tools to qdrant_search to avoid no-op execution.
Basic verification completed
Regression checks and real Telegram runs passed; @NBCKB_Bot can now receive and return valid answers online.
missing_params persistence and recovery.ask_user precision, and iterate prompt templates accordingly.本周延续第五周“已上线可用”的基础,重点从“能跑”转向“稳定可用”。核心目标是提升多轮对话中的上下文延续能力,减少重复追问,并让图引擎在不确定场景下具备更清晰的决策路径。
多轮补参与线程恢复闭环完善
已打通 AskUser -> checkpoint 挂起 -> 用户补充 -> 恢复执行 主链路,支持在同线程内恢复上下文继续检索与回答,减少“重新从头问一遍”的体验问题。
通用反思决策模块落地
pre/post 两阶段反思逻辑已统一到同一决策框架,支持 continue_retrieval / ask_user / revise_answer / accept_answer 四种动作,并结合不确定度阈值、hop 上限、反思轮次上限做收敛控制。
回答生成稳态与兜底能力增强
对回答生成流程补齐了重试与异常兜底;当回答阶段异常或反思轮次超限时,系统会给出可解释降级结果,避免静默失败或空响应。
Telegram / Discord 在线运行时一致性增强
两端 gateway 都统一接入 full graph 主流程,并对过滤、异常回退、消息格式适配、分段发送等行为进行了补齐,线上入口行为更一致。
测试与回归验证
现有非集成测试已完整回归通过:pytest -m 'not integration' 结果为 260 passed, 2 deselected,覆盖图引擎、记忆服务、平台适配、检索与工具运行时等关键模块。
本周完成后,系统已从“单轮可用”进一步推进到“多轮可持续交互”阶段:
discourse_query、github_search),但当前运行时主路径仍以 qdrant_search / memory_fetch 为主,工具闭环仍需继续补齐。discourse_query / github_search 在运行时的标准化接入与超时/幂等策略对齐。Following Week 5’s online availability milestone, this week focused on stability and multi-turn quality: preserving context across clarification turns, reducing repeated follow-up questions, and making graph decisions more deterministic under uncertainty.
Clarification-resume loop improved
Completed AskUser -> checkpoint suspend -> user supplement -> resume flow, enabling in-thread continuation instead of restarting from scratch.
Unified reflection decision framework
Implemented a unified pre/post reflection decision set:
continue_retrieval / ask_user / revise_answer / accept_answer, with uncertainty threshold, hop caps, and reflection-round limits.
Answer generation resilience upgrades
Added retry and fallback behavior for answer composition, with clearer degradation behavior when composition fails or post-reflection rounds are exhausted.
Telegram/Discord runtime consistency improvements
Both gateways now align on full-graph execution behavior, including filtering, fallback handling, output formatting, and segmented delivery.
Regression verification
Non-integration regression tests passed:
pytest -m 'not integration' → 260 passed, 2 deselected.
The system moved from “single-turn usable” to a more reliable multi-turn stage:
discourse_query, github_search), while runtime execution is still centered on qdrant_search / memory_fetch.discourse_query / github_search with timeout/idempotency alignment.嗨 @IrisNeko,
感谢你一直以来的稳定更新,我们也很高兴看到你始终都稳步推进。
根据你上周和本周的更新,我们希望了解你是否愿意拉一个 Telegram 试用群,把委员会成员邀请进去先体验一下。
我们提出这个想法是为了取得更好的整体效果。委员会成员更了解 CKB 的实际开发场景与痛点,能够在你处理具体问题和数据时给到一定的帮助。
期待你的回复。
祝好,
行天
代表星火计划委员会
Hi @IrisNeko,
Thank you for your consistent updates; we’re also glad to see you steadily making progress.
Based on your updates last week and this week, we’d like to know if you’re willing to create a Telegram trial group and invite committee members to try it out first.
We proposed this idea to achieve better overall results for the Nervos Brain project. Committee members are more familiar with CKB’s real development scenarios and pain points, and can provide assistance when you handle specific issues and data.
Looking forward to your reply.
Best regards,
Xingtian
On behalf of the Xinghuo Plan Committee
cc: @zz_tovarishch , @yixiu.ckbfans.bit , @Hanssen
本周承接第六周“多轮可持续交互”阶段的工作,重点从“机制已经具备”推进到“关键路径真正闭环、且后续可以被稳定评测”。核心目标有四个:
discourse_query / github_search 从协议层定义走到图执行主路径可调用。日志治理与诊断视图补齐
已对常见第三方库日志进行了统一降噪处理,补充了 quiet_loggers 与 third_party_level 控制项,降低了测试和运行期的无关日志干扰。同时把工具执行过程的摘要信息接入到图状态与 trace_summary 中,使得一次回答至少可以追踪到“执行了哪些 tool、各自成功/为空/失败”的最小诊断视图,而不再只能看到最终回答文本。
工具执行闭环推进到运行时主路径
本周把 discourse_query 与 github_search 从“schema 已存在但主路径未接通”的状态推进到了可被 RetrieverPlanner -> RetrievalExecutor -> ToolRuntime 实际调用的状态。具体包括:
RetrieverPlanner 归一化阶段已允许这两个 tool 保留,不再强制回退到 qdrant_search。ToolRuntime 为二者补齐了 handler。execute_tool,不再为新增 tool 走特殊旁路逻辑。回答链路的可解释性继续增强
在原有“回答生成稳态与兜底能力增强”的基础上,本周补充了 tool 级别的错误码与执行摘要,使回答不仅能在失败时兜底,也能在 trace 中解释失败原因。例如工具执行异常会落到统一错误结构中,而不是静默吞掉。这样后续排查时,可以区分“模型答错”“检索为空”“工具执行异常”“预算截断”等不同问题来源。
多轮评测集第一版落地
已新增 evaluation/week7_multiturn_eval.jsonl 作为第一版多轮 benchmark 输入集,并新增配套的 loader / validator,确保每条 case 至少满足:
case_id;success_criteria;expected_signals 用于后续自动比对。平台稳定性回归增强
Telegram / Discord 两端都补充了:
Week 7 相关回归验证通过
本周相关测试,结果为:
78 passed, 1 warning
覆盖范围包括 tool runtime、graph executor、logging system、Discord/TG runtime 以及 evaluation dataset 验证。
本周最重要的新工作,不是单纯“加了几条样例”,而是把后续多轮评测的基本方法论先定下来。这里单独展开说明。
当前项目虽然已经具备多轮补参、反思分流、回答兜底等机制,但如果没有稳定 benchmark,任何关于“效果更好了”的结论都只能靠主观感受。尤其是多轮系统,很容易出现下面几类错觉:
因此本周没有直接上“评分 dashboard”,而是先做 benchmark 输入层。原因很简单:没有稳定输入,就没有稳定指标;没有稳定 case,任何分数都不可复现。
本周设计 benchmark 时,刻意没有把重点放在开放式知识问答上,而是围绕 Nervos Brain 当前最关键的系统能力来建样例。也就是说,这份 benchmark 的目标不是测试“模型懂不懂 CKB”,而是测试下面这些系统行为是否发生:
qdrant_search。换句话说,这份 benchmark 更像是“系统工作流 benchmark”,而不是“百科知识 benchmark”。
本周评测集按三类任务拆分:
solution_recommendation(方案推荐)development_guidance(开发指导)troubleshooting(排障定位)这样拆分的原因是,这三类任务对应了系统最典型、也最容易出错的三种工作模式。
solution_recommendation 关注的是:
development_guidance 关注的是:
troubleshooting 关注的是:
这三类覆盖面并不等于项目全部任务,但已经足够形成一个可复用的最小 benchmark 骨架。
本周不是只记录“问题文本”,而是给每条 case 设计了完整结构。单条 case 至少包含以下字段:
case_id
用于保证 case 可追踪、可比对、可回归。
category
明确任务类别,避免把推荐类、开发类、排障类混在一起统计,导致指标失真。
conversation
必须是多轮结构,而不是单句问答。因为我们本周的目标就是验证多轮补参与恢复,而不是单轮回答质量。
expected_signals
这是本周 benchmark 设计里最关键的一层。它不直接判断最终答案“好不好”,而是先判断系统行为“有没有发生”。例如:
sdk_language;github_search;discourse_query 与 qdrant_search;success_criteria
这里记录的是回答级别的成功标准,例如:
expected_signals 的区别在于:前者看流程动作,后者看回答结果。expected_signals 和 success_criteria如果只有 success_criteria,我们只能看最后回答像不像“还行”,但无法知道它是通过正确流程得到的,还是偶然答对的。
如果只有 expected_signals,我们又只能知道系统“做了动作”,但不能判断最终产出的答案是否真的可用。
所以本周采用“双层判定”思路:
第一层:流程层 benchmark
检查有没有正确 ask_user、有没有正确选 tool、有没有沿线程继续执行。
第二层:回答层 benchmark
检查最终回答是否引用充分、是否尊重约束、是否满足任务目标。
这两层拆开之后,后面出现 bad case 时就能更快定位:
本周这 6 条样例不是随机写出来的,而是围绕当前系统最值得验证的机制构造出来的:
推荐类样例
用来测试用户目标在第二轮收缩后,推荐路径是否跟着变化。
例如从“我想做 demo”进一步细化到“前端集成、JS/TS”。
开发指导类样例
用来测试系统是否会在缺语言/版本时追问,并在得到补参后输出更贴近实际工程的步骤或示例来源。
排障类样例
用来测试系统在日志不充分、版本冲突、文档与代码不一致时,是否会优先保守地继续收集证据,而不是直接“拍脑袋诊断”。
本质上,这些 case 优先覆盖的是“高频失败模式”,而不是“知识点覆盖率”。这也是第一版 benchmark 更适合工程迭代的原因。
虽然本周还没有把完整的自动评分 runner 做出来,但流程已经定型,后续可以直接接上:
jsonl benchmark。conversation。ask_user_questiontrace_summaryexpected_signals 做流程级检查。success_criteria 做结果级检查。后续如果继续扩展,这个流程可以自然演进成:
这是一个取舍问题。当前最缺的是“统一输入格式”,不是“再写一个复杂脚本”。
如果没有先把 case 结构稳定下来,直接写 runner 很容易导致:
所以本周先完成的是:
这样下一周只需要在这个基础上补 runner 和聚合输出,而不需要推倒重来。
本周也明确看到了第一版评测集的边界:
expected_signals 还需要进一步细化成更严格、可自动比对的字段。因此,本周的 benchmark 工作更准确地说是“评测基线搭建完成”,而不是“评测体系完成”。
本周完成后,系统进入了一个新的阶段:
discourse_query / github_search 不再停留在协议层,而是进入了主路径可执行状态。trace_summary 已能表达最小工具执行信息,但还没有形成更结构化的统一诊断报告。This week focused on turning the newly-added multi-turn mechanisms into a more testable and operationally reliable system. The four core goals were:
discourse_query / github_search from protocol-only definitions into the real runtime path.Logging and observability cleanup
Added logger quieting controls and surfaced per-tool execution summaries into graph state and final trace summaries.
Runtime tool-loop coverage expanded
discourse_query and github_search now survive planner normalization, have dedicated runtime handlers, and align with timeout / idempotency / normalized execution behavior.
Better answer-path explainability
Tool-level execution failures now map into clearer traceable error states instead of disappearing behind generic failures.
First multi-turn benchmark dataset landed
Added a structured jsonl evaluation set plus loader/validator utilities, covering recommendation, development-guidance, and troubleshooting tasks.
Platform stability regression improved
Added Discord/Telegram fallback-path and long-message segmentation tests to protect key runtime edge cases.
Week 7 regression validation
In the nervous-brain mamba environment, the Week 7 related suite passed:
78 passed, 1 warning.
The most important outcome this week was not just “adding several examples”, but defining the first benchmark methodology for multi-turn system evaluation.
This benchmark is designed to test system behavior rather than generic knowledge recall. Its purpose is to verify whether the system:
The dataset is divided into three task types:
solution_recommendationdevelopment_guidancetroubleshootingEach case contains:
case_id for stable tracking;category for split-level reporting;conversation with at least two turns;expected_signals for workflow-level expectations;success_criteria for answer-level expectations.This two-layer design is deliberate:
This separation matters because it lets us diagnose whether a failure came from planning, retrieval execution, or answer composition instead of treating every bad answer as the same class of issue.
The benchmark construction strategy this week prioritized failure modes over topic breadth. The six seed cases were manually designed around the most important multi-turn risks:
The intended evaluation flow is now clear:
jsonl;expected_signals;success_criteria;This week intentionally stopped at dataset + validator rather than overbuilding a scoring runner too early. The reasoning was simple: without a stable input format, any automated benchmark script would be fragile and constantly changing. By fixing the dataset contract first, future runner and dashboard work can build on a stable base.
感谢您的建议,
我上周对系统做了基础的评测,并计划在这周拉一个Telegram试用群,邀请委员会的成员提前体验。同时欢迎在体验中提出建议,来帮助我改善系统。
Best regards.
Hi IrisNeko, 目前论坛已经接入AI翻译工具,Spark不再强制要求项目在Talk上沉淀的内容需采用双语版本
期待项目的持续发展!
本周重点从离线评测和工具闭环,转向 Telegram 群内测、线上部署和真实使用反馈。目标不只是让 Bot 能在测试群里回答问题,而是观察它在真实群聊环境中的稳定性:是否会误触发、是否能隔离不同用户上下文、是否能正确检索官方文档和论坛资料、是否会过度追问,以及线上异常能否通过日志快速定位并修复。
本周关注的核心问题包括:
群聊中不同用户的上下文是否会互相串扰。
Bot 是否会错误插入普通群聊。
用户连续追问时,系统是否能正确理解上文。
检索结果、引用和 source 选择是否稳定。
Agent 是否存在过度追问、答非所问、格式异常或无限重试等影响体验的问题。
多用户同时提问时,Telegram runtime 是否能并发处理。
用户上传文本文件或图片时,系统是否能把附件纳入回答上下文。
线上问题是否能通过日志、debug event 和回归测试快速定位。
本周开始在 Telegram 群中进行真实内测。测试不再只依赖人工构造的离线样例,而是让用户围绕 CKB、Nervos、Fiber、CCC、Agent 钱包、链上应用、游戏项目、新手学习路线和官方资料等主题进行自然提问和连续追问。
真实群测暴露出的行为比离线样例复杂得多:用户会用“它”“这个”“继续说”“有没有靠谱资料”“官方没有教程吗”这类短句承接上文;不同用户会在同一个群里交叉提问;用户也会直接纠正 Bot“你是不是回复错问题了”。这些反馈帮助我们把问题从“可能发生”变成“有日志、有复现、有测试”的工程闭环。
本周完成了 Telegram 群内短期记忆隔离改造,将上下文粒度调整为“群/频道 + 用户”。系统默认读取同一用户在同一群内最近 20 条与 Bot 相关的消息,并注入 full graph 作为短期上下文。
这样可以避免同一个群里 A 用户和 B 用户的对话互相污染,同时支持“我刚才问了什么”“继续说”“看看上文”这类短期追问。AskUser 的 checkpoint 恢复逻辑也同步改成按用户隔离,避免 B 用户误恢复 A 用户的补参流程。
群聊触发策略也进行了修复:
私聊直接响应。
群聊中只有被 @、被回复,或收到 Bot 命令时才响应。
普通群聊直接忽略,不发送 typing,不写入 memory,也不进入 graph。
这让 Bot 在群内的行为更自然:用户需要它时可以明确唤起,不需要时它保持安静。
内测中确认了一个重要运行时问题:如果 Telegram polling 串行处理所有 update,不同用户同时提问时会互相排队,复杂问题会明显拖慢其他用户。
本周将 Telegram polling gateway 改成多线程并发处理:
不同用户/会话可以并发进入 graph。
同一个 chat + user 的消息仍按顺序处理,避免同一用户连续追问乱序。
Telegram API 发送、debug event 写入和 feedback 写入增加锁保护。
SQLite memory 连接配置调整为允许多线程访问。
这部分没有采用多进程,避免引入额外的进程间状态同步和本地 Qdrant/SQLite 资源竞争。
服务器重启后曾出现一次严重线上问题:Agent 不断调用模型 API,但用户一直收不到回复。定位后发现根因不是模型,也不是网络,而是 Telegram sendMessage 返回 400 后异常向外抛出,导致当前 update 的 offset 没有推进。polling 下一轮又拿到同一个 update,于是同一条消息被反复处理,造成模型 API 被重复调用。
本周修复为:
sendMessage 失败后先从 MarkdownV2 降级为纯文本重试。
如果 reply 发送失败,再去掉 reply_to_message_id 作为普通消息重试。
process_update 失败也不阻塞 offset 推进,避免同一 update 无限重放。
补充发送失败、offset 推进和 fallback 发送的回归测试。
这项修复显著降低了线上 Bot 因 Telegram 格式或 reply 状态异常导致循环消耗模型调用的风险。
本周将 GitHub 文档库和 Nervos Talk 论坛数据接入当前 runtime,形成多库检索能力。系统启动时会加载多个 retrieval backend,并在日志中打印已加载的后端,方便确认线上运行环境是否接入了论坛库和文档库。
同时修复了论坛检索的超时问题。此前 discourse_query 会在大库上重建或扫描过多候选,导致线上工具调用超过 10 秒并被取消。修复后改为先通过 SQLite 做更小范围的候选预筛,再进行排序,从而让论坛检索能在服务器配置下稳定返回。
工具调用默认超时时间也从 10 秒延长到 60 秒,避免慢但有效的检索被过早取消。
真实对话中暴露出一个新的检索路由问题:用户问“有没有比较靠谱的资料可以看?”或“官方没有比较好的教程吗?”时,LLM 会自然生成 filters.source=official_docs,但当前数据库中官方文档实际 source 是 github_docs。这导致 qdrant_search 很快返回空结果,然后系统给出“知识库没有足够证据”的错误回复。
本周对此做了更稳的架构调整:
新增 retrieval source registry,统一定义当前合法 source。
planner prompt 注入合法 source 和每个 source 的内容范围。
运行时对 LLM 生成的 filters 做 normalize 和 validation。
将 official_docs、docs、documentation 等别名映射到 github_docs。
对带 filter 的 qdrant_search 空结果,在预算允许时自动去掉 filter 重试一次。
广泛资料类问题优先走快速 vector search,避免无过滤条件下进入 BM25/fuzzy/exact 慢路径。
当前实际可用 source 包括:
github_docs:官方文档、docs.nervos.org、RFC、CKB/CCC/Fiber 仓库文档、SDK 文档和代码示例。
nervos_talk:Nervos Talk 论坛帖子、社区讨论、Spark/grant/proposal、生态项目介绍和真实案例。
这让 source 选择不再依赖模型猜测,也避免了模型生成不存在的 source 后直接导致检索为空。
本周对 full graph 中的 InfoGap、RetrieverPlanner、Reflection、DirectAnswer、AnswerComposer 等 prompt 进行了集中调整。
调优重点不是增加大量关键词规则,而是让 LLM 更清楚地区分:
哪些信息需要问用户;
哪些信息属于公开资料,应由系统检索;
什么时候应该基于合理默认假设继续回答;
什么时候应该说明证据边界,而不是泛泛拒答;
什么时候可以直接利用上文回答,而不是重新检索或重复追问;
用户在纠正 Bot 答非所问时,应直接道歉并重新聚焦,而不是继续检索旧问题。
同时,路由层增加了保护逻辑:
ask_user 不再输出硬编码兜底回复。
如果没有真正的用户私有必填信息,graph 不应进入 ask_user。
post-answer reflection 如果把公开资料缺口错误路由到 ask_user,会被改路由到继续检索、改写或回答。
“你是不是回复错问题了”“答非所问”“不是这个问题”这类质量反馈会直接进入 direct answer,不触发资料检索。
这部分修复了“靠谱资料”追问被错误回复成 Fiber/testnet 默认假设,以及用户纠错后反而收到“知识库证据不足”的问题。
本周补充了 Telegram 附件处理能力。此前系统只能识别用户上传了文件或图片,但不会下载,也不会把内容交给模型。
现在支持:
文本类文件下载和内容注入,包括 .txt、.md、.json、.yaml、.csv、.log、常见代码文件和配置文件。
图片下载后保存本地路径,并在回答生成阶段作为 image input 传给支持多模态的 LLM。
对附件设置大小限制:文本文件 256KB,图片 20MB。
明确不支持 PDF,避免引入复杂解析和不稳定依赖。
这让用户可以在 Telegram 中上传日志、代码片段、配置文件或截图,让 Bot 直接基于附件内容回答。
为了支持群内测问题定位,本周补充了更完整的 debug 信息,包括节点耗时、LLM 调用摘要、检索证据数量、tool trace、reflection 决策、route decision、终止证据不足原因等。
同时补充了服务器部署相关支持:
增加 Linux 版 Telegram Bot 重启脚本。
调整 environment.yml,去掉 Windows 专属依赖,改成跨平台最小环境。
整理 .gitignore,避免提交真实配置、日志、群聊记录、周报、个人文档和缓存文件。
清理 GitHub 仓库历史,确保公开仓库不包含敏感信息和本地资料。
通过日志确认线上 bot 进程启动时间、加载后端和实际请求链路。
本周内测的主要价值,是让系统问题从“离线样例中可能发生”变成“真实用户已经遇到”。几个比较典型的反馈包括:
用户希望 Bot 能理解连续追问,而不是每轮都像重新开始。
用户不希望 Bot 插入普通群聊。
当用户说“我是萌新,你自己决定”时,Bot 应该主动给方案,而不是继续追问。
当用户问“有没有靠谱资料”“官方有没有教程”时,Bot 应该主动查官方文档,而不是给知识库证据不足。
当用户说“你是不是回复错问题了”时,Bot 应该识别这是对回答质量的反馈,而不是继续沿着旧问题检索。
技术回答需要稳定引用资料来源,否则用户难以判断可信度。
对代码示例类问题,即使证据不完整,也应给出清晰的骨架和边界说明。
响应时间需要继续优化,尤其是复杂问题经过多节点 graph 后等待时间较长。
用户希望可以上传文件、日志或截图,让 Bot 直接分析。
这些反馈说明,当前系统的核心挑战已经不只是“能不能回答”,而是“是否像一个可靠、不过度打扰、能持续理解上下文、能使用资料和附件的群内助手”。
本周围绕 Telegram 群内测暴露的问题补充和运行了多组回归测试,重点覆盖:
群内同用户上下文读取。
不同用户记忆隔离。
AskUser checkpoint 按用户恢复。
群聊 mention-only 触发策略。
未触发消息不写入 memory。
多线程并发处理与同一用户消息顺序保证。
Telegram sendMessage Markdown/plain/detached fallback。
offset 在异常场景下仍推进,避免同一 update 无限重放。
多库检索、论坛检索性能和工具 60 秒超时。
qdrant_search broad resource 查询优先 vector path。
source registry 注入、source alias 规范化和空结果 fallback。
response-quality feedback 直接回复,不进入检索。
post-answer ask_user 防护和 ask_user 硬编码兜底移除。
Telegram 文本文件下载、内容注入和图片作为 LLM image input。
CSAT、feedback、BadCase 逻辑回归。
阶段性相关回归测试结果为:
192 passed, 2 warnings
后续需要把本周真实群测 bad case 继续沉淀为标准评测样例,避免类似问题再次回归。
本周完成后,系统从“群内可测”进一步推进到“线上可诊断、可修复、可回归”。主要成果包括:
Telegram 群内测开始形成真实反馈闭环。
群内上下文实现按用户隔离。
Bot 在群聊中默认只响应明确触发,减少打扰。
不同用户问题可以多线程并发处理。
GitHub 文档库和 Nervos Talk 论坛库进入 runtime 检索路径。
检索 source registry 和 filter 校验让资料检索更稳定。
过度追问、回答滞后、答非所问、引用缺失、Markdown 异常等真实问题得到系统修复。
Telegram 发送失败不再导致 update 重放和模型 API 无限调用。
Telegram 文本文件和图片开始进入模型上下文。
Debug 日志和部署脚本更适合线上排查。
响应延迟仍需要优化。复杂问题经过多节点 graph、检索、反思和回答生成后,耗时仍偏长。
Prompt 仍需要根据真实内测继续调优,特别是“主动给默认方案”和“避免编造”之间的平衡。
引用稳定性还需要继续观察,尤其是连续追问、资料链接和代码示例场景。
source registry 目前是静态配置,后续最好从实际 archive metadata 自动生成或定期校验。
附件支持目前覆盖文本文件和图片,暂不支持 PDF、音频转写和复杂 Office 文档。
内测反馈还没有形成结构化问卷和统计指标,目前仍偏人工观察。
部署流程还可以继续标准化,例如补充 systemd、健康检查和日志轮转。
下周重点不再是继续堆功能,而是围绕 Telegram 群内测反馈做系统调优、用户评估设计和线上运行稳定性提升。
将过度追问、回答滞后、引用缺失、上下文误用、检索为空、答非所问、发送失败等问题归类,形成可复盘的 bad case 列表。
重点优化小白问题、连续追问、代码示例、公开资料检索、默认假设选择和证据边界说明。
让 planner 更稳定地理解 github_docs、nervos_talk 等 source 的内容范围,并考虑从 archive metadata 自动生成 source 提示,减少手工维护。
设计一份简短问卷,用于收集用户对回答质量、上下文理解、响应速度、引用可信度、追问体验、附件分析能力和整体可用性的主观评价。
初步统计满意度、常见失败类型、用户是否需要重复解释上下文、是否认为 Bot 打扰群聊、是否愿意继续使用等指标。
把真实群测中暴露出的典型问题转成可重复运行的评测样例,形成“内测反馈 → 测试集 → 回归验证”的闭环。
基于 node timings 和 LLM trace 分析耗时瓶颈,优先优化简单问题、常见追问和资料类查询的快答路径。
在现有重启脚本基础上,补充更稳定的守护方式和日志观察流程,降低内测期间人工维护成本。
Hi Spark Program Committee,
感谢委员会一直以来的支持,也感谢各位持续 review 每周进展。
根据第 8 周的项目进展,我想申请从已批准的 Nervos Brain Grant 剩余额度中拨付下一笔 $1,000 USDI installment。
目前项目已经从离线开发、工具闭环和回归测试阶段,进入 Telegram 群内测、线上部署和真实用户反馈阶段。第 8 周的重点不再只是让 Bot “能回答”,而是验证它在真实群聊环境中是否能稳定、自然、可诊断地运行。
进入真实 beta testing 阶段后,项目相比早期原型开发产生了更多持续成本,主要包括:
截至第 8 周,Nervos Brain 已经不只是一个本地原型,而是进入了真实 Telegram beta feedback loop。申请这笔 $1,000 USDI installment 将用于支持之前开发阶段的开销与剩余的 beta 测试、线上稳定性优化、专家咨询、LLM API 消耗、评估体系完善和最终交付工作。
请将这笔 installment 发送到此前用于接收首笔启动资金的同一 CKB/JoyID 地址:
ckb1qrgqep8saj8agswr30pls73hra28ry8jlnlc3ejzh3dl2ju7xxpjxqgqqywl8cx055zewvgzjtw3w0zndmgr4ml5q5qhpdcd
同时欢迎委员会的各位进入 Telegram 测试群参与内测。
Best regards,
IrisNeko
@IrisNeko 你好,感谢你提交第 8 周周报与中期拨付申请。
委员会已完成体验与讨论,并一致认可目前 Nervos Brain 的整体质量与可用性(尤其是你把 Telegram 群内测做成了“可复现问题 → 修复 → 回归测试”的工程闭环)。
第二期预算已拨付:
交易哈希:0x7481daa872c9d775b741a1061a1512f87c8cc62b55c4930040da2a928e5c064f
同时有两点建议,供你后续规划参考:
运营资金路径建议:我们也认为这个项目具备对社区长期产生帮助的潜力;若后续进入更偏“正式运营 / 持续服务”的阶段,建议将运营性资金需求转向 **Community Fund DAO 申请,以匹配其长期支持定位。
模型选择建议:后续迭代请慎重选择模型与组合策略,尽量在经济性(成本/延迟)与准确率/稳定性之间取得更稳的平衡,并在周报中持续公开关键指标与取舍依据,便于社区理解与复核。
期待你继续推进后续交付,也欢迎持续把关键 bad case 与评测集沉淀出来,形成对生态可复用的参考资产。
祝好
行天
代表 Spark Program 委员会
回顾近期的 bad case,主要原因是 prompt 设置过于保守:一方面表现为对用户频繁追问,另一方面是查资料不够积极。此外,上周的数据库问题也是因模型未触发多库联合调用引起的。总体来看,系统并没有严重的设计或架构问题,后续优化 prompt 和调用逻辑即可解决。
本周重点承接 Telegram 群内测反馈,继续修复真实使用中暴露出来的回答质量、检索覆盖、消息格式和部署可复现问题。
相比第八周,本周不再只关注“Bot 能否在群里稳定跑起来”,而是进一步关注:
面向真实用户问题时,Agent 是否会主动检索足够资料。
技术教程是否能优先使用现成框架和真实 API,而不是给出空泛 TODO。
Telegram / Discord 长回复、代码块、链接和引用格式是否稳定。
模型路由是否过于保守,是否需要更多 medium/high 档参与复杂任务。
检索数据和 Qdrant 数据库是否能被其他人快速重建和部署。
本周修复了 Telegram 长回答在分段发送时容易破坏 Markdown 格式的问题。
之前系统主要依赖 MarkdownV2 字符串切分,长代码块或复杂格式在接近 Telegram 4096 字符限制时容易被硬切,导致代码块、链接、引用等格式错乱。
本周改为使用 telegramify-markdown,将 Markdown 转成 Telegram Bot API 的 text + entities 结构,再按实体边界安全分段发送。这样 Telegram 端不再主要依赖 parse_mode=MarkdownV2,长回复中的代码块、标题、列表、链接、引用和中英文混排都更稳定。
同时保留了 plain text fallback:如果 Telegram 发送 entities 失败,会移除 entities 和 parse_mode 后按纯文本重试,保证消息不会因为格式问题整体发送失败。
本周进一步补齐了 Discord 端能力,使其不再只是一个较薄的收发适配层,而是更接近 Telegram 端的完整 runtime。
Discord 和 Telegram 的消息格式机制不同,因此本周没有复用 telegramify-markdown,而是为 Discord 引入 markdown-it-py 辅助 Markdown block 解析,并实现 Discord 专用安全分段逻辑。长 fenced code block 会按 Discord 2000 字符限制拆分,同时保证每段代码块闭合,避免长代码、链接、列表和引用在分段时破坏格式。
同时补齐了 Discord 端多个线上必需能力:
回复 Bot 消息时携带被回复内容快照,避免“继续说”“改一下”这类短追问丢失上下文。
guild 默认仍采用 mention-only 策略,普通未提及消息不会触发 graph,也不会写入 memory。
接入 memory service,处理后的用户消息和 Bot 回复会按 Discord guild/channel/thread/user 维度隔离写入。
接入 feedback store,支持回答元数据、CSAT button 和 /feedback 文本反馈。
接入 debug JSONL,用于后续定位检索、反思、引用和响应耗时问题。
支持下载较小的文本附件,如 .txt、.md、.json、.yaml,并注入 graph 上下文。
发送 payload 默认禁用 allowed_mentions,避免生成内容误 ping 用户或角色。
run_discord_bot.py 也同步补齐了 feedback、debug、memory context、延迟预算、附件大小、allowed guild/channel 等配置入口。Discord 端现在可以作为和 Telegram 平行的线上入口继续测试。
mini_high 档位本周发现模型路由过于保守,很多本应需要更认真推理的问题仍停留在 low 档,导致检索规划、反思判断和技术回答质量不稳定。
为此新增了第四个业务档位:
low = gpt-5.4-mini + low
mini_high = gpt-5.4-mini + high
medium = gpt-5.5 + low
high = gpt-5.5 + high
mini_high 用作低成本深思考档,主要用于 InfoGap 判断、检索规划、轻量反思、引用初筛和公开资料判断。这样简单问题仍可走 low,复杂但不必直接升级到 gpt-5.5 的任务可以走 mini_high,减少 low 和 medium 之间的断层。
同时更新了 router prompt 和默认 fallback,让技术判断、检索规划和反思节点更容易使用 medium / high 档,而不是几乎全部落到 low。
群内测中暴露出一个明显问题:用户提出 TS/JS、CCC、CKB 转账等实际开发问题时,Agent 有时没有主动检索相关文档、代码和论坛讨论,而是基于有限证据给出空泛回答。
本周将检索策略调整为“默认统一多库检索”。也就是说,在技术教程、SDK/API、真实框架、代码示例、生态项目和用户纠错场景下,Agent 默认应把 docs、github_code、forum 看作一个统一知识库,而不是过早只查单一来源。
主要调整包括:
InfoGap prompt 更明确要求技术类问题主动检索。
RetrieverPlanner prompt 默认使用无 source filter 的 qdrant_search。
只有用户明确限定来源时,才优先专项查询。
AnswerComposer 要求新手教程优先使用现成框架、官方示例和可运行路径。
Reflection 会把“用户要 TS/JS,但证据只有 Go SDK”判为偏题或证据不足。
对“为什么不用 CCC”这类用户纠错,不再直答猜测,而应检索复核。
这项修复的目标不是写死 CCC 规则,而是让 Agent 在面对真实技术问题时更主动、更全面地检索可用资料。
为了补齐群内测中暴露的资料缺口,本周新增爬取并入库了多类资料。
新增文档资料包括:
CCC 相关 llms 文档。
Spore / DOB cookbook。
Spore docs。
DOB decoder standalone server。
Spore DOB 0 / DOB 1。
xUDT logos 相关仓库资料。
这些资料分别进入 GitHub 文档库和 GitHub 代码库,补强了 CCC、Spore DOB、xUDT、生态项目示例和真实代码检索能力。
本周也新增了 run_web_text_ingest.py,用于将 llms.txt 这类纯文本 Web 文档规范化入库,避免以后遇到类似资料时只能临时手动处理。
本周进一步完善了 Qdrant server 模式。
当前 Bot runtime 使用 Docker Qdrant server 作为向量服务,避免 Telegram / Discord 多进程同时访问本地 Qdrant 目录造成锁冲突。
本周明确了数据发布边界:
GitHub 仓库存 SQLite archive DB、source JSONL 和必要的大文件 LFS 对象。
data/qdrant_server/ 是 Docker 运行时目录,不提交 GitHub。
其他人 clone 仓库后,通过脚本从 archive DB 重建 Docker Qdrant 三个 collection。
云端 Qdrant 也可以用同一迁移脚本从 archive DB 重建。
新增 bootstrap_qdrant_server.sh 后,部署流程更清晰:
git lfs pull
bash bootstrap_qdrant_server.sh
脚本会启动 Docker Qdrant,并从公开可提交的 archive DB 重建 docs、forum、github_code 三个 collection。
当前三库验证结果为:
nervos_docs: 1336
nervos_talk_user_discussions: 13057
nervos_github_code: 23247
这意味着其他人 clone GitHub 仓库后,只需要准备环境、拉取 LFS、填写自己的密钥和 Bot token,就可以较快恢复 Bot 的检索能力。
本周继续梳理公开仓库和本地私有运行数据之间的边界。
公开仓库应包含:
代码、测试、脚本和配置模板。
可公开的 docs / forum / github_code 检索数据。
Qdrant 重建脚本和部署说明。
Docker compose 和环境文件。
公开仓库不包含:
config.yaml
LLM API key
Telegram / Discord Bot token
群聊记录
debug events
runtime logs
memory DB
Docker Qdrant server 运行目录
这样既能保证项目可复现部署,又不会把甲方或测试群的私密信息带进仓库。
本周最典型的内测反馈是:用户并不是只需要“有一个回答”,而是需要“像一个懂开发路径的助手”。
例如,当 TS/JS 用户想写 CKB 转账小应用时,Agent 不应该让用户从底层 Cell、Lock、OutPoint 全部自己实现,也不应该只给一个全 TODO 的骨架。更合理的方式是主动检索 CCC、官方示例、代码仓库和论坛讨论,然后基于现成框架给出最小可运行路径。
这类反馈推动本周重点从“回答是否流畅”转向“回答是否真的有帮助”。对应的工程变化包括:
更主动地检索公开资料。
默认统一查多库,而不是过早限定来源。
更激进地使用 medium / high 推理档位。
对教程类回答提出更高要求,避免空泛 TODO。
对 Telegram / Discord 格式和长消息发送做稳定性修复。
本周围绕格式、模型路由、检索和部署进行了多组回归验证。
重点覆盖:
Telegram Markdown entities 分段。
Telegram send payload 中 entities 与 parse_mode 的兼容逻辑。
Discord Markdown 安全分段和 2000 字符限制。
Discord reply context、CSAT、feedback、debug、memory、文本附件处理。
长代码块、标题、列表、链接、引用等格式发送。
mini_high profile 加载和 fallback。
full graph router 对 mini_high 的识别。
统一多库检索 planner 行为。
Qdrant server migration。
GitHub docs/code ingestion。
Composite retriever 多库合并。
clone 后 Qdrant 三库重建流程。
阶段性验证包括:
tests/test_qdrant_server_migration.py tests/test_retrieval_unit.py: 12 passed
tests/test_discord_bot_protocol_adapter.py tests/test_discord_bot_runtime.py tests/test_platform_formatter.py tests/test_telegram_bot_runtime.py tests/test_telegram_bot_protocol_adapter.py: 96 passed
以及针对 ingestion、retrieval、formatter、Telegram runtime、Discord runtime 和 full graph 的多组专项测试。
本周完成后,项目进入了更接近可交付测试的阶段:
Telegram 长消息格式问题基本解决。
Discord runtime 和长消息格式能力基本补齐。
模型路由不再只有 low / medium / high 三档,新增 mini_high 缓冲层。
Agent 对技术类问题的主动检索策略更明确。
docs / forum / github_code 三库统一检索链路更清晰。
CCC、Spore DOB、xUDT 等生态资料进入检索库。
Docker Qdrant server 可以从 GitHub 中的 archive DB 快速重建。
公开仓库和私密运行数据的边界进一步稳定。
真实用户问题仍需要继续积累 bad case,特别是教程类、代码类和生态项目类问题。
Agent 是否真的会稳定选用 CCC、Spore 等现成框架,还需要继续通过群内测观察。
Discord 端已经补齐核心 runtime,但仍需要真实频道环境继续验证按钮交互、附件和长消息体验。
Qdrant server 部署流程已有脚本,但还可以继续补充健康检查和长期守护方案。
内测反馈还需要问卷化,否则主观反馈难以量化比较。
下周重点从功能修复转向最终交付前收敛,主线是 Nervos Talk MCP、最终测试和用户反馈收集。
将 Nervos Talk / forum 查询能力整理成 MCP 工具,使 Agent 能在需要社区讨论、生态案例、历史争议和用户经验时更直接地调用 Talk 数据,而不是只依赖离线检索库。
对 Telegram、Discord、Qdrant server、三库检索、模型路由、formatter、feedback、memory 和部署脚本做最终集成测试,重点验证 clone 后重建、线上 Bot 长时间运行、长消息格式和真实问答链路。
发放内测问卷并整理 Telegram / Discord 真实使用反馈,重点收集回答质量、检索可信度、上下文理解、响应速度、追问体验、引用可信度和整体可用性评价。
把 CCC 教程、TS/JS 转账、Spore DOB、Fiber、xUDT、Nervos Talk 社区讨论等真实问题整理进 evaluation dataset,用于最终回答质量回归。
根据最终测试和用户反馈微调主动检索、回答生成、反思和模型路由策略,重点避免空泛 TODO、证据不足却强答、忽略用户技术栈等问题。
本周重点从“群内测问题修复”推进到“交付前工程收敛”。相比第九周继续补功能,本周更关注项目是否能被部署方理解、复现、运行和验收。
本周核心目标包括:
完成 Nervos Talk MCP 和 Talk forum 定时增量更新能力。
补齐工程文档,让部署方 clone 仓库后能按文档快速部署。
验证 docs / forum / github_code 三个检索库的重建、增量更新和 Git LFS 发布边界。
继续测试 Telegram / Discord 两端真实 Bot 链路。
将典型问答问题整理为 evaluation dataset,方便后续回归。
修复内测中暴露的 reply 上下文误用问题。
优化检索数据库召回能力和回答链路,减少“有资料但搜不到”“搜到了但链路过慢”的问题。
本周实现了只读 Nervos Talk MCP,用于实时查询公开 Nervos Talk / Discourse 数据。
第一版 Talk MCP 只做读取,不写论坛、不访问私有分类、不让普通 Bot 问答触发爬虫。工具能力包括:
talk_search:按关键词搜索公开讨论。
talk_get_topic:读取指定 topic 的帖子内容。
talk_get_post:读取指定 topic 内的单条 post。
talk_latest:查看最新公开讨论。
同时补充了 Talk forum 定时增量更新服务。离线 forum archive 和 Qdrant collection 由定时 ingest 服务更新,默认频率为 24 小时。这样普通用户问答仍然只读检索库,不会在请求过程中触发慢爬虫、写库副作用或论坛 API 限流问题。
这项设计把“实时查看论坛”和“更新本地检索库”分开:MCP 负责即时查询,定时任务负责数据库增量维护。
本周继续完善 GitHub 文档库和代码库的增量更新能力。
之前 GitHub 数据主要依赖全量爬取,更新成本较高,也不利于长期运维。本周新增基于 repo commit / manifest / state 的增量刷新流程,使系统可以识别哪些仓库发生变化,并只处理需要更新的部分。
增量更新边界也进一步明确:
data/ingest_state/ 是本机运行游标,记录上次爬到哪里,不提交 GitHub。
data/manifests/ 是公开数据版本说明,可以提交。
增量 JSONL 默认进入临时目录,不直接覆盖 canonical source JSONL。
archive DB 仍然是可复现数据源,Qdrant server 是运行时向量服务。
本周也实际验证了 docs、forum、github_code 三类数据的增量流程。个别较大的 GitHub 仓库在本机网络环境下按需拉取 blob 时出现 TLS 中断,但这属于本机网络不稳定导致的外部问题,不影响脚本设计;后续部署到网络更稳定的服务器时可继续跑完整增量。
本周重点补齐了公开工程文档,使项目从“代码和脚本基本可用”推进到“别人 clone 后可以按文档部署和运维”。
新增和精修的文档包括:
README.md:作为项目公开入口,说明项目定位、快速启动、数据布局和文档索引。
docs/deployment.md:fresh clone 后的部署流程,包括环境、配置、Qdrant、Bot 启动和健康检查。
docs/configuration.md:解释 config.yaml.example 中 LLM、retrieval、Bot、logging 等配置区。
docs/retrieval-data.md:解释 archive DB、Qdrant server、Git LFS 和三库重建关系。
docs/runtime-operations.md:说明 Telegram / Discord / Qdrant / Talk 增量服务的日常运维。
docs/mcp.md:说明 Telegram MCP 与 Nervos Talk MCP 的定位和环境变量。
docs/testing-and-acceptance.md:整理部署验收和推荐回归测试命令。
docs/troubleshooting.md:整理 Docker、LFS、Qdrant、token、mamba 环境和 Bot 无响应等常见问题。
文档中只写公开流程、占位符和通用命令,不写真实 token、API key、群聊原文、debug log 或测试服务器私密路径。
本周进一步梳理了检索数据的交付方式。
当前项目中有三类检索数据:
docs:Nervos / CKB / CCC / Spore 等文档资料。
forum:Nervos Talk 社区讨论。
github_code:GitHub 代码和示例仓库。
Docker Qdrant server 是线上运行时向量数据库,里面有三个 collection。archive DB 是可提交、可迁移、可重建的数据源。部署方 clone 仓库后,通过 Git LFS 拉取 archive DB,再用迁移脚本重建 Docker Qdrant collection。
本周确认并调整了 Git LFS 策略:体积较大的 SQLite archive DB 走 Git LFS,避免普通 Git 历史膨胀;Qdrant Docker 运行目录不提交,部署时从 archive DB 重建。
这样可以兼顾两个目标:
GitHub 仓库可以保存公开可复现的数据源。
部署环境可以快速恢复 Qdrant runtime 数据库。
本周继续测试 Discord Bot 链路,重点关注它是否能作为 Telegram 之外的第二个线上入口。
Discord 端已经具备以下能力:
guild / channel allowlist。
mention-only 触发策略。
回复 Bot 消息时携带 reply context。
Markdown 长消息安全分段。
feedback、CSAT、debug event 和 memory context。
禁用 allowed_mentions,避免生成内容误 ping 用户或角色。
实际启动测试时也确认了 Discord 的一个部署注意事项:如果 Bot runtime 请求了 privileged intents,而 Discord Developer Portal 没有开启对应权限,会报 PrivilegedIntentsRequired。这不是代码崩溃,而是 Discord 平台权限配置问题。部署方需要在 Developer Portal 中开启对应 intent,或者后续按最小权限原则关闭不必要 intent。
本周将评测样例目录整理为两类:
evaluation/ai_generated_cases.jsonl:人工设计 / AI 辅助生成的基准样例。
evaluation/human_collected_cases.jsonl:真实内测或人工收集的问题样例。
这个划分比按 week 命名更清晰。后续如果用户反馈某个回答不好,可以直接脱敏后追加到 human_collected_cases.jsonl,并写明失败模式和验收标准。
目前真实坏例子不多,很多问题本质上来自数据库缺口、软件 bug 或 prompt 策略不稳定,而不一定是单个回答样例本身有长期复现价值。因此当前阶段以“轻量记录、后续积累”为主。
本周继续跟进 Telegram 群内测中出现的上下文问题。
测试中发现一种具体问题:用户回复某条旧消息,并用“用小白版解释一下”这类短句追问时,Bot 有时没有围绕被回复消息回答,而是被普通最近历史中的其他话题带偏。
排查后发现,runtime 虽然能看到 reply_to_message_id,但 reply context 和同用户最近历史会一起进入 graph。对于短追问来说,被回复消息才是直接锚点,普通最近历史反而可能污染模型判断。
本周修复为:
如果当前消息明确 reply 了某条消息,优先只使用被回复消息内容作为上下文锚点。
reply 场景不再混入普通最近历史,避免 WASM / Fiber 等旧话题抢上下文。
如果平台没有提供被回复消息内容,会明确告诉模型“被回复内容不可见,不要从普通历史记录猜测”。
debug event 增加 reply_to_content_preview、conversation_context_preview、recent_messages_preview,方便后续定位。
Telegram 和 Discord 两端都补充了对应回归测试。
这项修复后,用户使用 Telegram / Discord 的原生回复功能时,Agent 更容易围绕被回复消息回答,而不是凭最近记忆猜测。
本周继续处理内测中暴露的检索问题:有些项目或讨论明明存在于 forum / docs / github_code 数据库里,但用户用自然语言点名项目时,普通向量、BM25、fuzzy、exact 融合仍可能没有把目标资料排到前面。
本周新增了由 LLM 检索规划器生成 regex_queries 的 hard recall 能力。这个设计没有把具体项目名写死到代码里,而是让 Planner 根据用户当前问题判断是否需要正则硬召回。例如用户点名真实项目、库、SDK、函数、类名、文件名、repo 或版本号时,模型可以生成短而具体的正则表达式;底层检索层只负责校验、限流、执行和融合。
实现边界包括:
regex_queries 挂在统一 qdrant_search step 上,不新增单独工具。
正则只作为 hard recall 子能力,与 vector / BM25 / fuzzy / exact 一起进入 RRF 融合。
底层拒绝空正则、过长正则、过宽泛正则、反向引用和明显危险 pattern,避免性能和安全问题。
debug trace 记录 regex 数量、有效数量、丢弃数量和丢弃原因,方便排查。
不做业务关键词硬编码,具体正则由模型根据问题生成。
这项优化解决的是“实体名硬召回”问题。例如项目名中有空格、连字符、下划线差异时,模型可以生成更宽松的匹配方式,避免论坛 topic 或 GitHub path 被普通语义检索漏掉。
本周也针对 full graph 链路过慢做了专项分析和 prompt 级优化。
实际评测发现,耗时主要不在 Qdrant 或 BM25/fuzzy/exact 检索,而在多轮 LLM 节点:模型路由、检索规划、pre-answer reflection、answer composer、post-answer reflection 和二次改写会叠加出很长等待时间。个别问题即使只是资料推荐,也可能因为过度谨慎进入多轮反思和改写。
本周坚持“不写业务硬规则”的原则,优先从 prompt 调整,让模型自己更早收敛:
模型档位路由 prompt 不再鼓励技术问题默认升高档位,而是按节点复杂度选择。
InfoGap prompt 明确“主动检索不等于多轮深检索”,资料推荐和学习路线类问题通常走 single。
RetrieverPlanner prompt 要求 single 默认只生成 1 个统一 qdrant_search step,不把历史错误回答和评测描述塞进 query。
Reflection prompt 要求证据足够覆盖核心问题时直接 accept_answer,不要为了更完整继续检索或二次改写。
AnswerComposer prompt 要求默认短答、贴题、先给可执行主线,资料类问题优先给 3-5 个入口和学习顺序。
引用要求更严格:只引用正文实际使用的证据,不把无关仓库、无关 README 或没有支撑正文断言的命中混进来源。
在人工作例回归中,这轮 prompt-first 优化让部分问题明显提速:Fiber agent 部署问题从接近 5 分钟降到 2 分钟左右,Fiber WASM 覆盖查询降到 1 分钟以内。CKB 新手资料推荐问题不再超时,但仍然偏慢,说明后续可能还需要通用链路机制优化,例如时间预算硬约束、post-reflection 最大改写次数或模型路由缓存。
本周对未提交改动做过多轮本地测试和主题拆分提交,覆盖依赖、Discord runtime、Talk MCP、GitHub 增量、工程文档、数据发布边界等内容。
阶段性验证包括:
mamba run -n nervos-brain pytest -q
以及针对 Telegram runtime、Discord runtime、full graph、formatter、retrieval、Qdrant migration、Talk MCP、GitHub ingest 等模块的专项测试。
本周也完成了 Git LFS 和 GitHub 远端同步,确保公开仓库中包含可复现部署所需的代码、文档、配置模板、脚本和公开数据源。
本周的重点不是继续增加新功能,而是把已有能力变成可交付状态。
主要收敛点包括:
Talk 数据从“离线论坛库”扩展为“只读 MCP + 定时增量更新”。
GitHub 文档和代码数据从“全量爬取”推进到“可增量刷新”。
Qdrant server 和 archive DB 的关系解释清楚,部署方知道哪些数据需要提交、哪些数据运行时重建。
README 和 docs/ 文档补齐,项目不再依赖口头说明。
Discord 链路开始进入真实部署测试。
evaluation dataset 开始按 AI 生成样例和人工收集样例分开维护。
Telegram / Discord reply 上下文误用问题得到针对性修复。
检索数据库增加 LLM 生成正则 hard recall,提升项目名、库名、文件名等实体召回能力。
full graph prompt-first 链路优化后,部分真实样例延迟明显下降,但简单资料类问题仍需继续优化。
本周验证重点覆盖:
Telegram reply context 不被普通最近历史污染。
Discord reply context 不被普通最近历史污染。
Telegram / Discord 长消息格式和分段发送。
Discord Developer Portal 权限配置问题定位。
Talk MCP 只读工具注册和调用边界。
Talk forum 24 小时定时增量服务设计。
GitHub docs/code 增量更新流程。
archive DB 到 Docker Qdrant server 的重建流程。
Git LFS 中数据库文件的提交和同步。
README 与 docs 文档命令、路径和安全边界。
evaluation dataset 文件命名和样例格式。
LLM 生成正则 hard recall 与普通检索融合。
prompt-first 链路优化后的人工样例回归。
阶段性专项测试包括:
tests/test_telegram_bot_runtime.py tests/test_discord_bot_runtime.py tests/test_full_graph.py: 137 passed
以及多组 py_compile、shell check、secret scan、git diff check 和 Qdrant collection 检查。
本周完成后,项目已经基本进入交付前最终测试阶段:
Telegram Bot 已经能在群内按 mention / reply 方式运行。
Discord Bot 已具备完整 runtime 能力,并开始真实链路测试。
docs、forum、github_code 三库可以通过 archive DB 和 Git LFS 复现。
Docker Qdrant server 作为运行时向量库的定位已经清晰。
Talk MCP 与 Talk forum 增量更新方案已经形成。
GitHub 文档和代码增量更新能力已经补齐。
公开工程文档已经覆盖部署、配置、数据、运行、MCP、测试和排障。
evaluation dataset 已经开始支持后续回答质量回归。
reply 上下文误用问题已经修复并补测试。
检索召回能力对真实项目名、代码路径和论坛 topic 更稳。
回答链路在不增加业务硬编码的前提下减少了一部分无效多轮反思和改写。
当前基础代码库和部署文档已经基本完成,后续重点不再是继续增加功能,而是完成最终验收材料和交付确认。
已完成部分包括:
基础代码库:vector DB + Graph Planning、Agentic RAG Bot 框架、Nervos Talk MCP、Discord / Telegram Bot、多模型路由和复合数据库。
文档与部署:README、功能说明、部署文档、配置说明、检索数据说明、MCP 说明、运行维护和故障排查文档。
剩余验收项目包括:
在社区招募测试人员,对回答质量、检索可信度、上下文理解、响应速度、追问体验和整体可用性进行打分,并整理测试结果。
录制完整演示,覆盖 Telegram / Discord Bot 问答、Nervos Talk 查询、检索引用、reply 追问、部署文档和数据重建流程。
按部署文档从 fresh clone 走一遍完整流程,确认 Git LFS 数据、Qdrant 重建、Bot 启动、Talk MCP、增量更新和核心问答案例都可用。
最后确认公开仓库不包含 token、API key、私钥、群聊原文、debug log、memory DB 和本机 runtime 数据。
Hi @IrisNeko ,
Nervos Brain 项目的剩余工作是否还顺利?继之前沟通过测试人员招募渠道后还未看到你们的消息。委员会希望了解你们的测试人员招募是否顺利,以及是否有可能在社区开放有限的公开测试?
不论有任何进展或者问题,都欢迎你继续在这里发布消息~~
祝好,
行天
代表 Spark Program 委员会
This post is the delivery report for:
Spark Program | Nervos Brain - A Global Developer Onboarding Engine and Cross-Language Hub Powered by Agentic RAG
Nervos Brain is designed to address two core bottlenecks in the Nervos / CKB ecosystem:
High onboarding friction for developers
CKB’s Cell Model, UTXO-based design, RISC-V VM, scripting model, and ecosystem-specific tooling create a steep learning curve for new developers.
Language and platform silos in technical knowledge
High-value knowledge is scattered across Nervos Talk, GitHub repositories, documentation, Telegram, Discord, and different language communities. This makes it harder for global developers to discover, verify, and reuse ecosystem knowledge.
The goal of Nervos Brain is not simply to build a Telegram or Discord bot. Those are only the first interaction surfaces.
The larger goal is to build a global developer onboarding engine and cross-language knowledge hub powered by Agentic RAG, so that developers and community members can ask complex Nervos / CKB questions, retrieve relevant source material, understand technical trade-offs, and receive structured answers with citations and feedback loops.
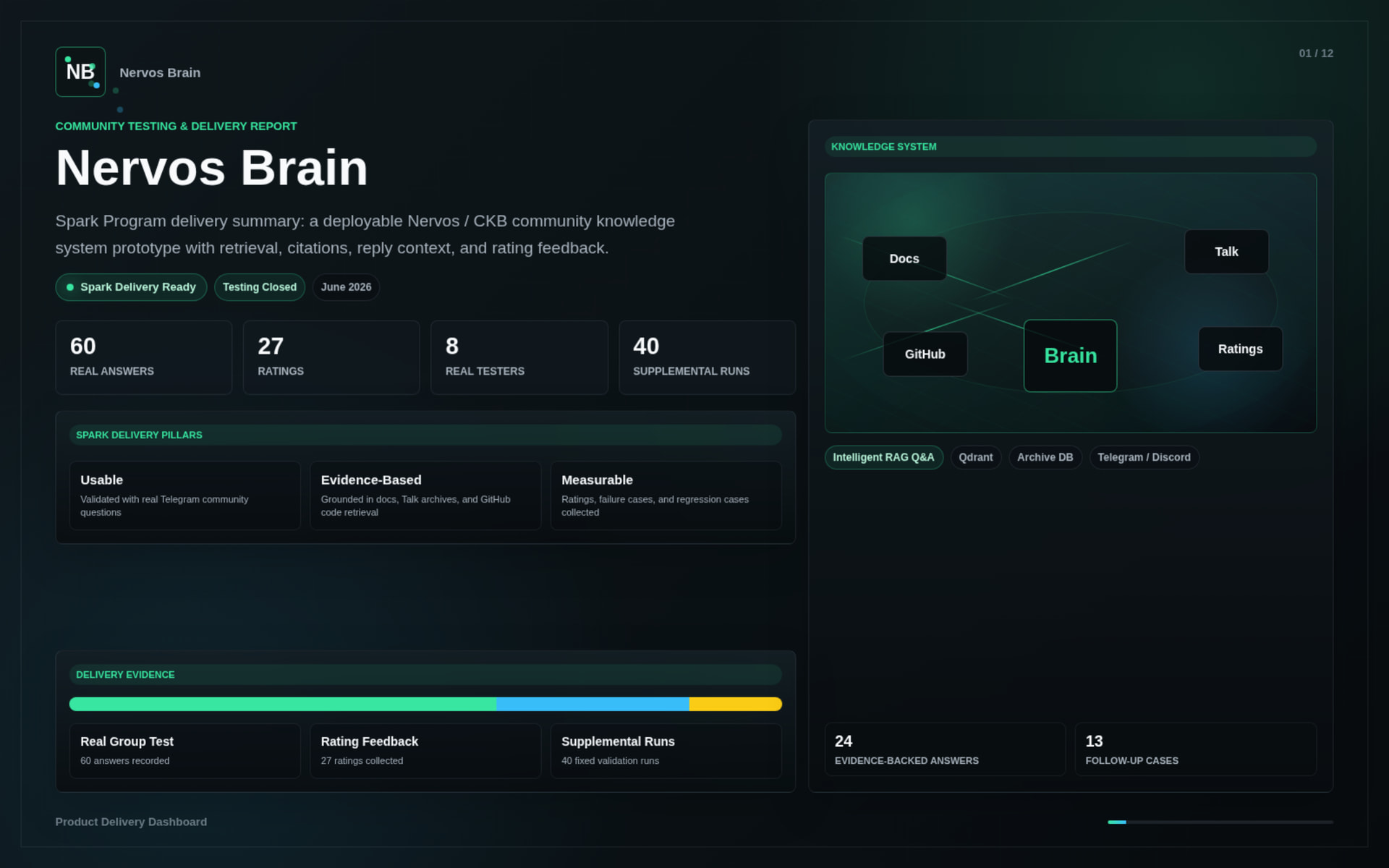
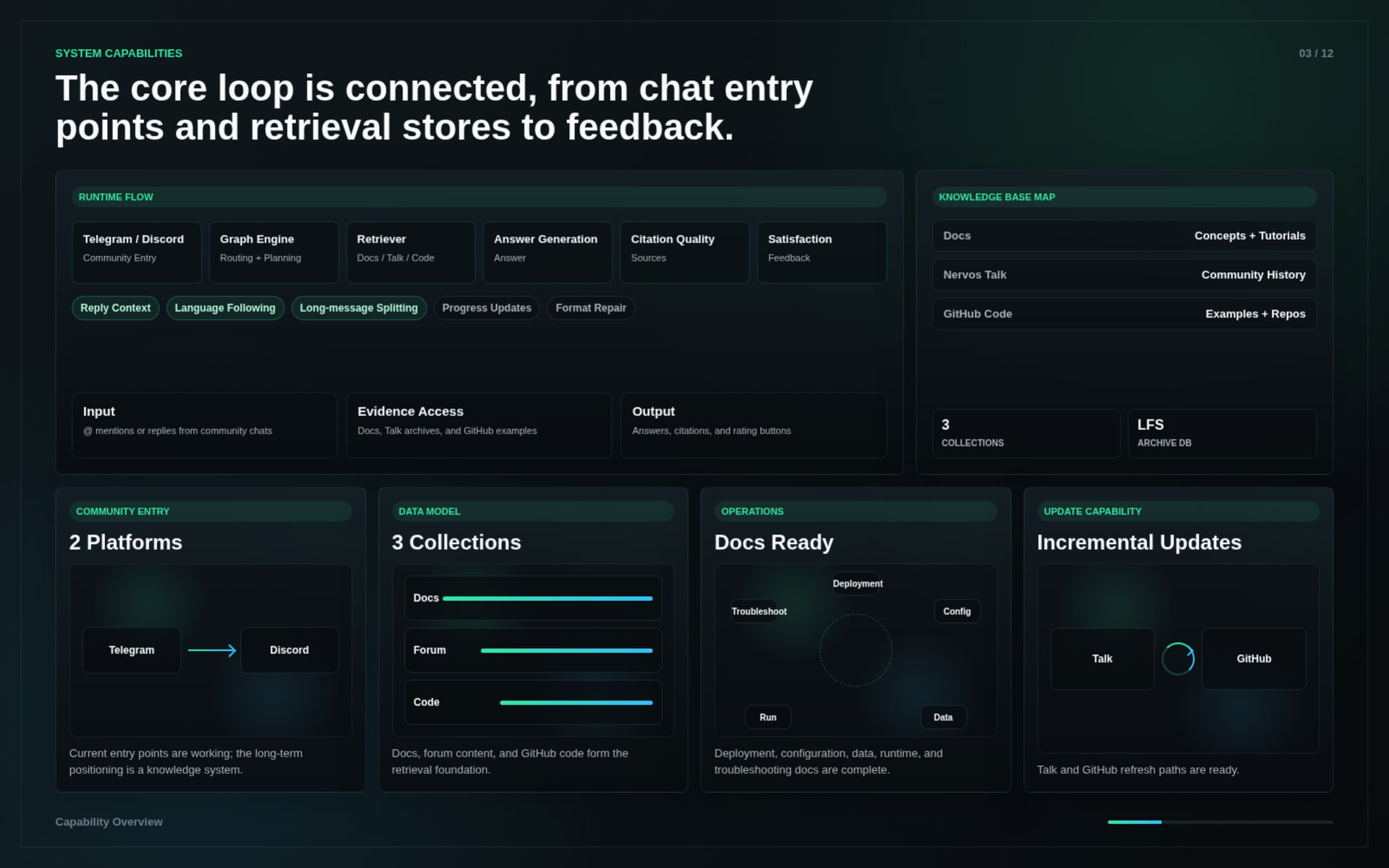
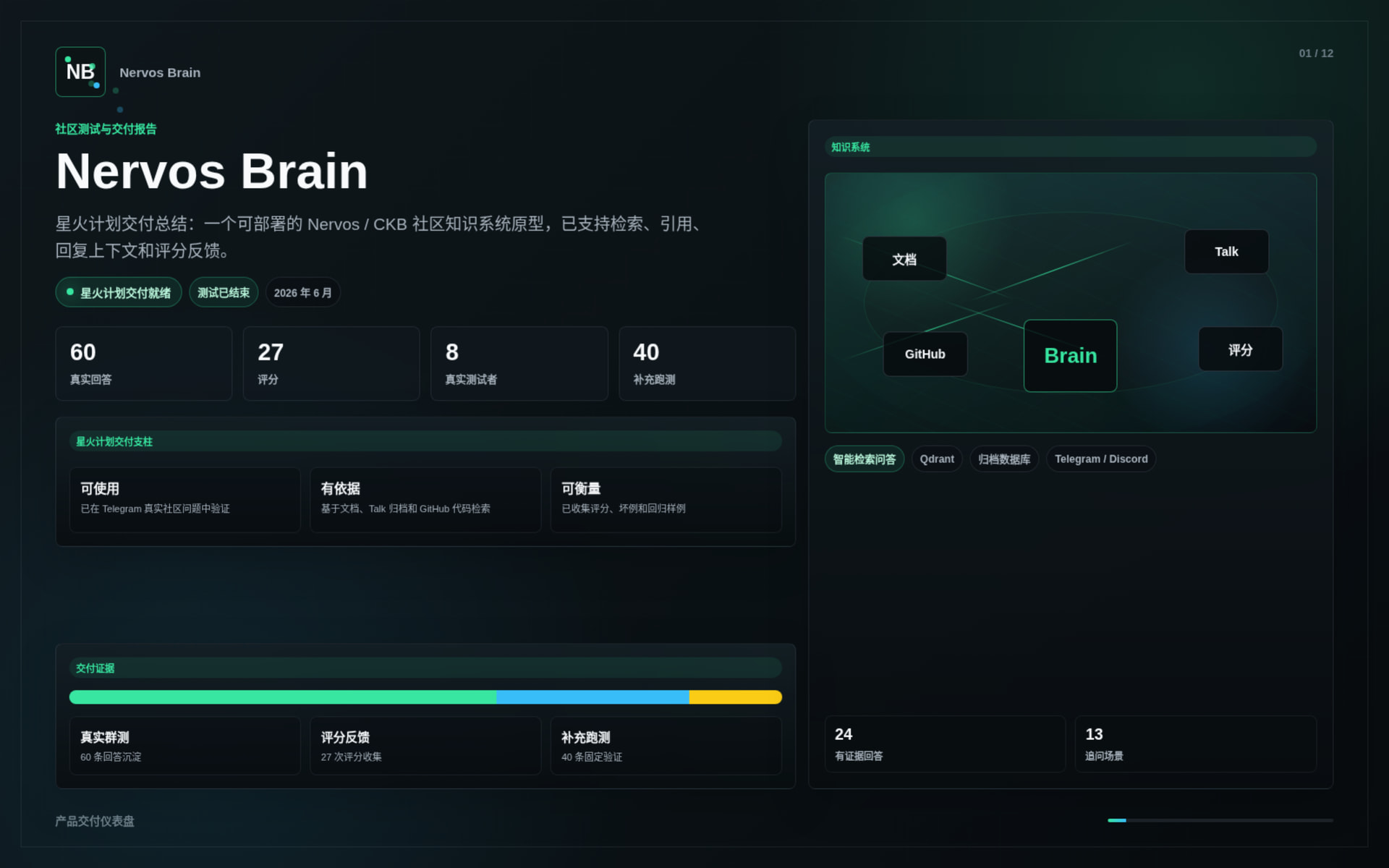
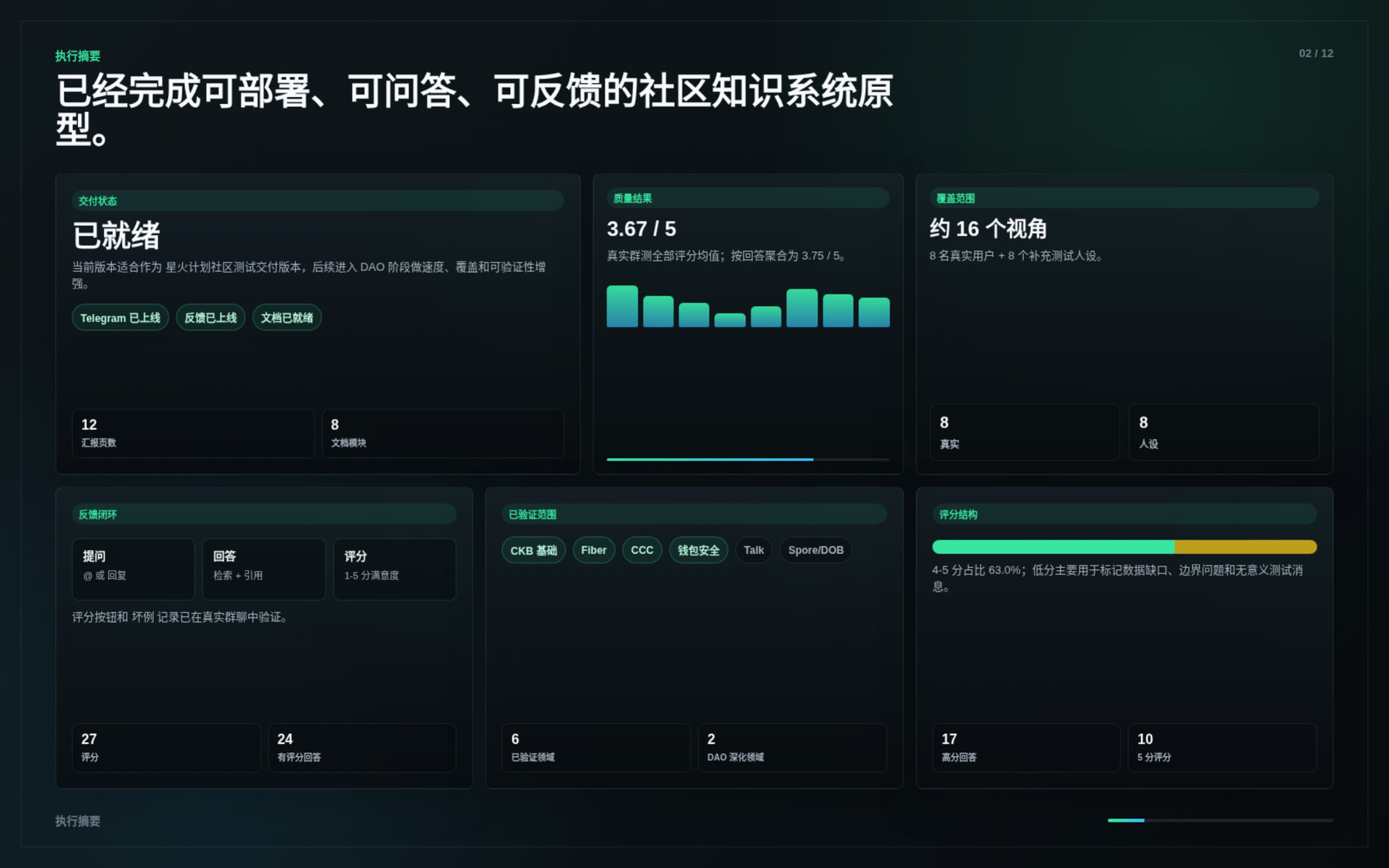
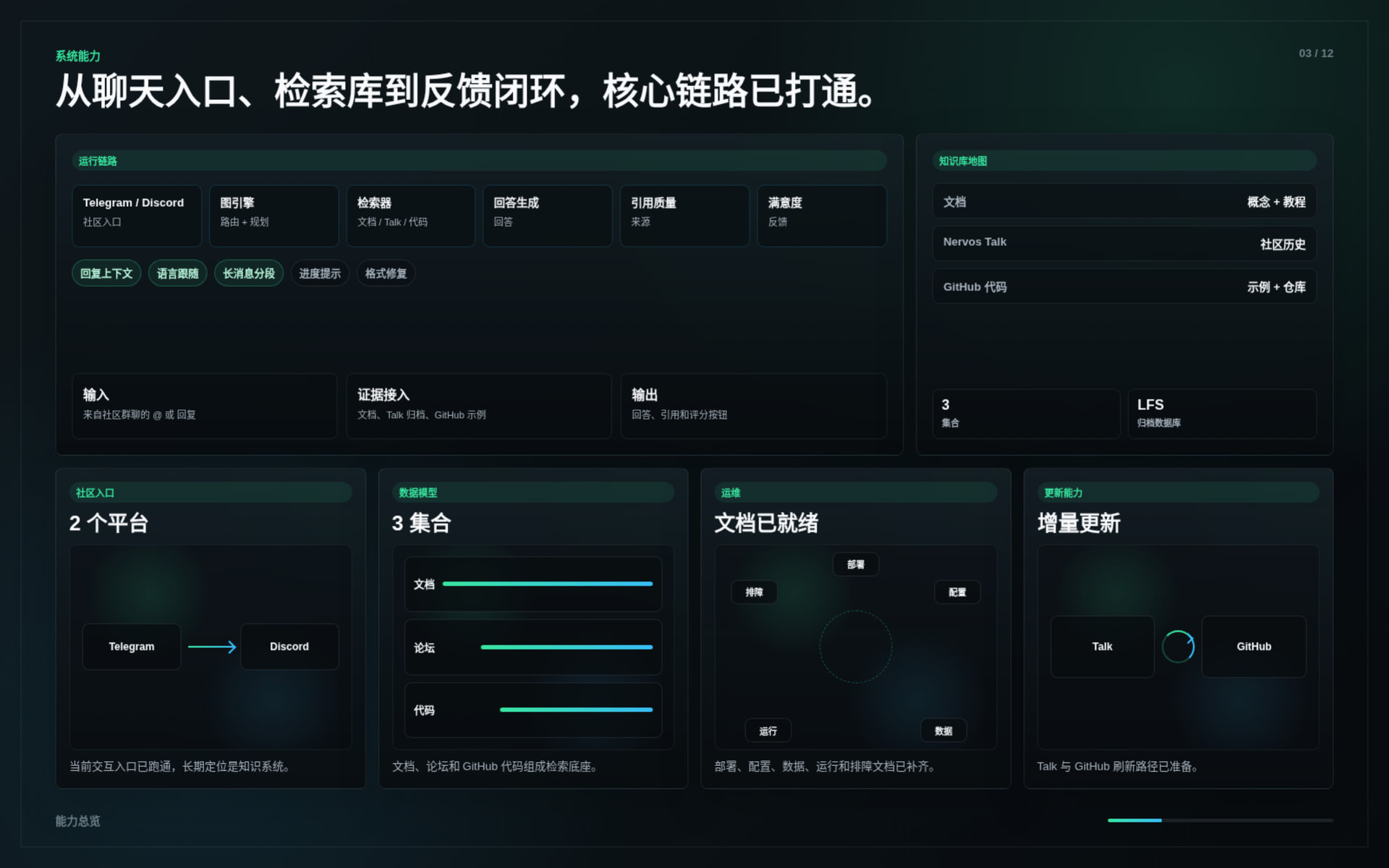
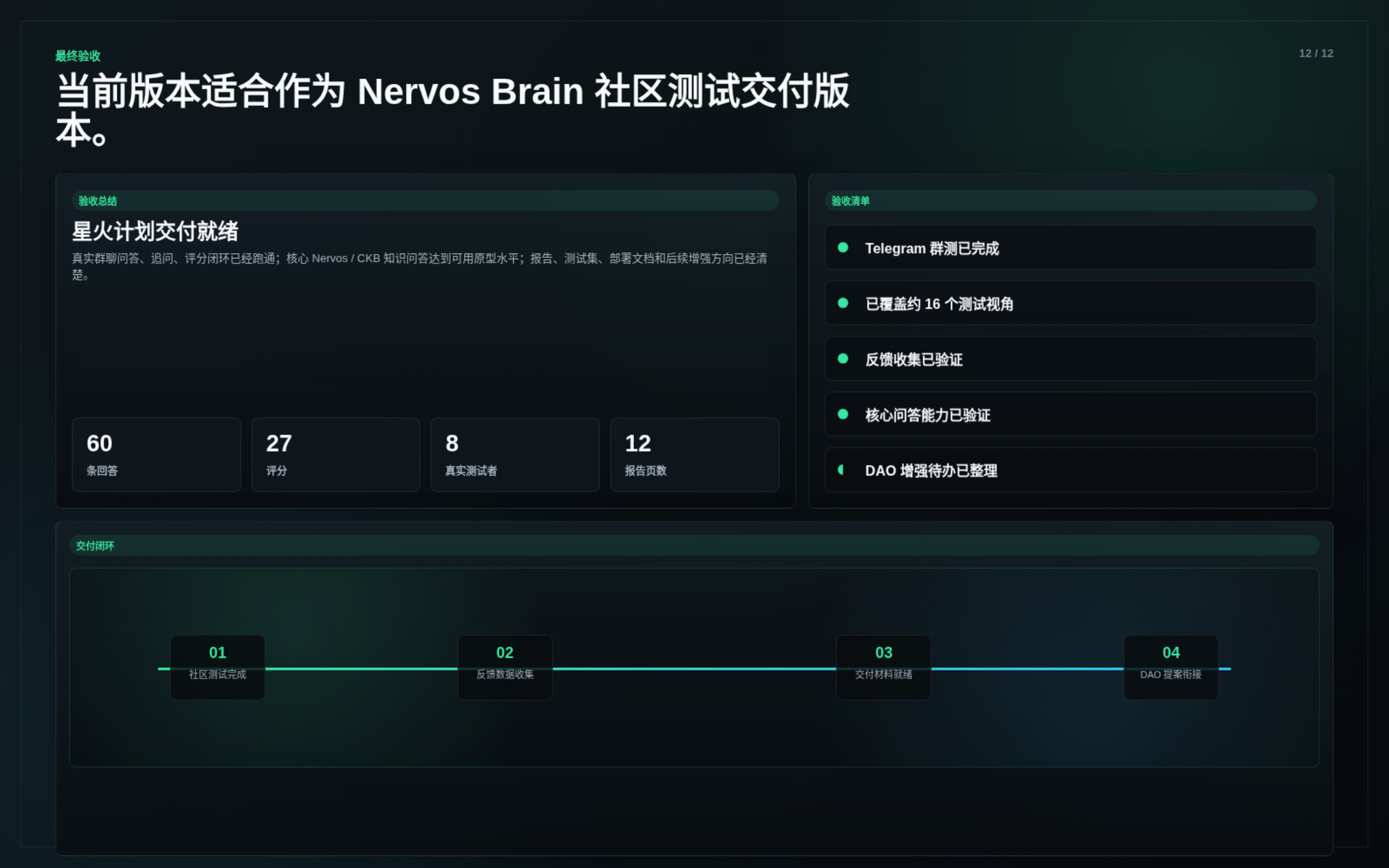
During the Spark Program stage, Nervos Brain completed the first delivery version of its core system.
The delivered work includes:
This delivery demonstrates that Nervos Brain can already support real Nervos / CKB onboarding and technical Q&A scenarios.
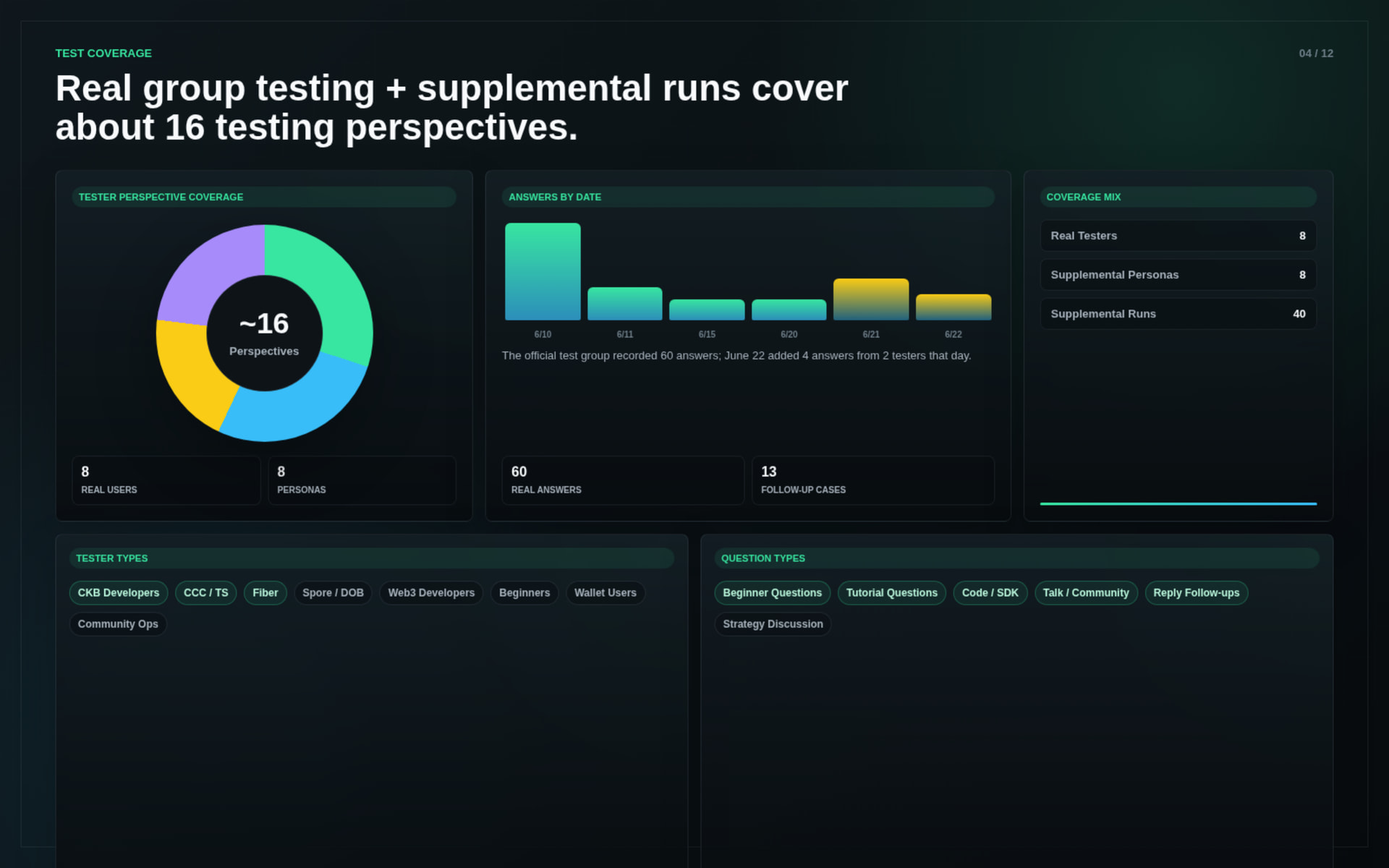
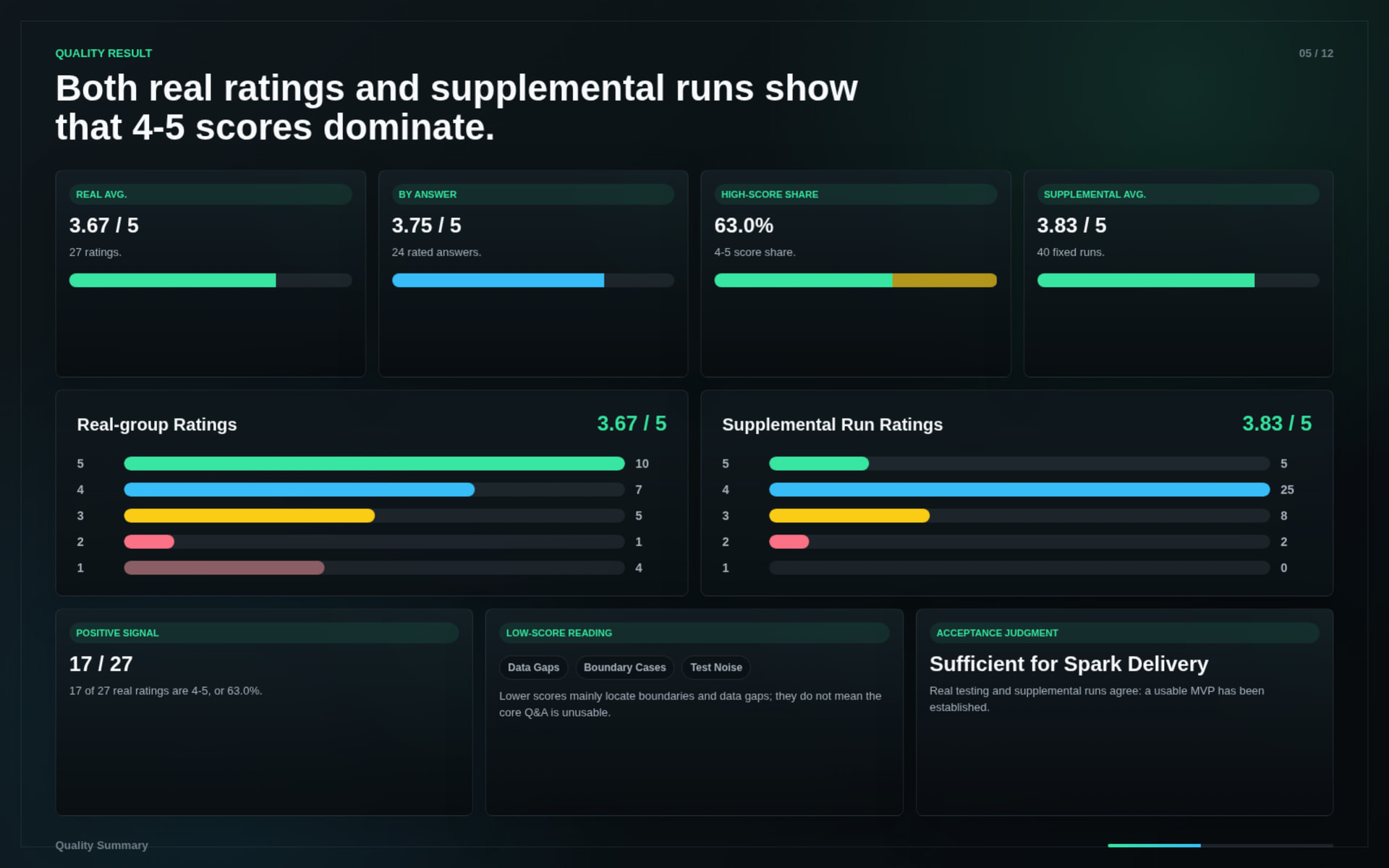
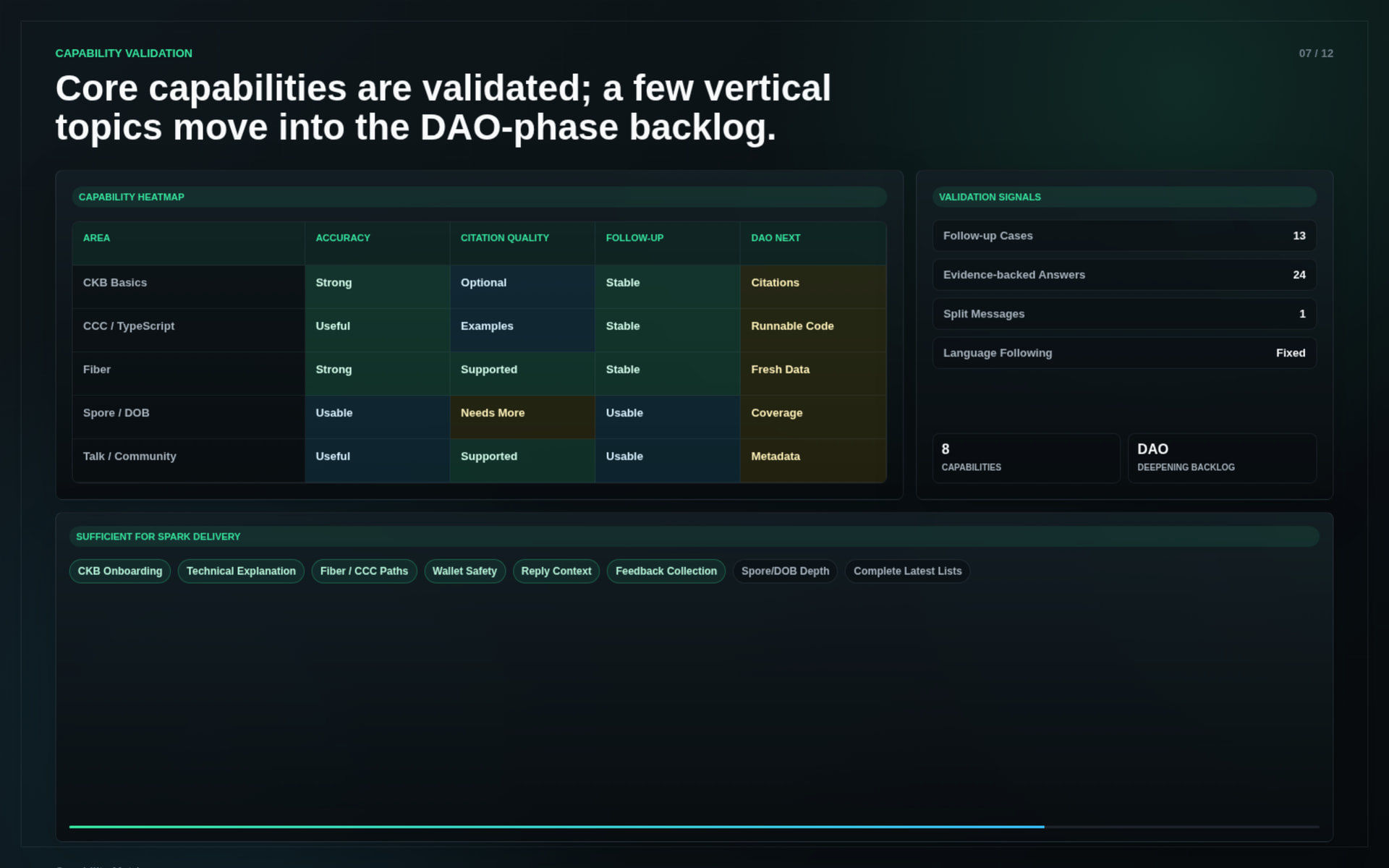
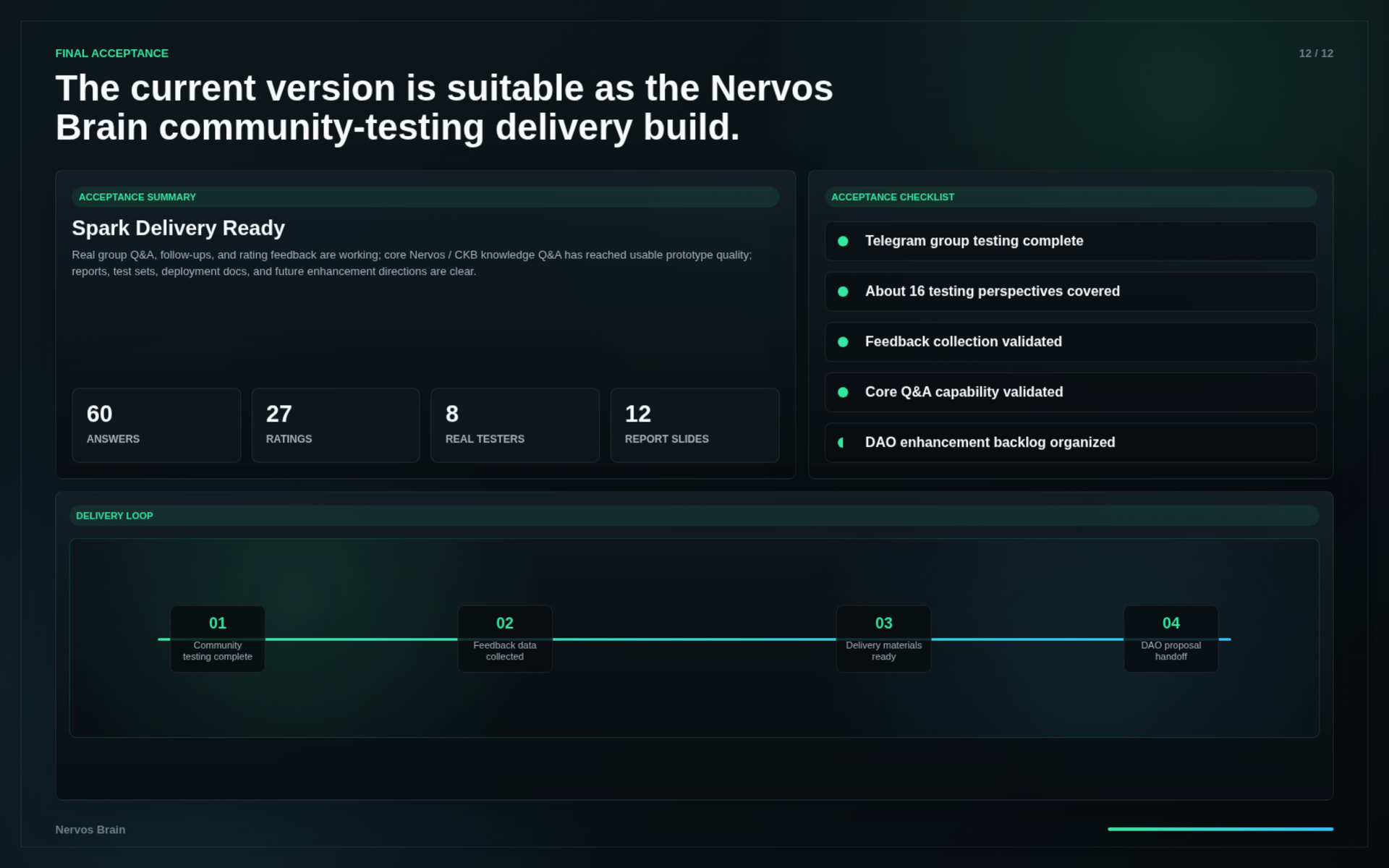
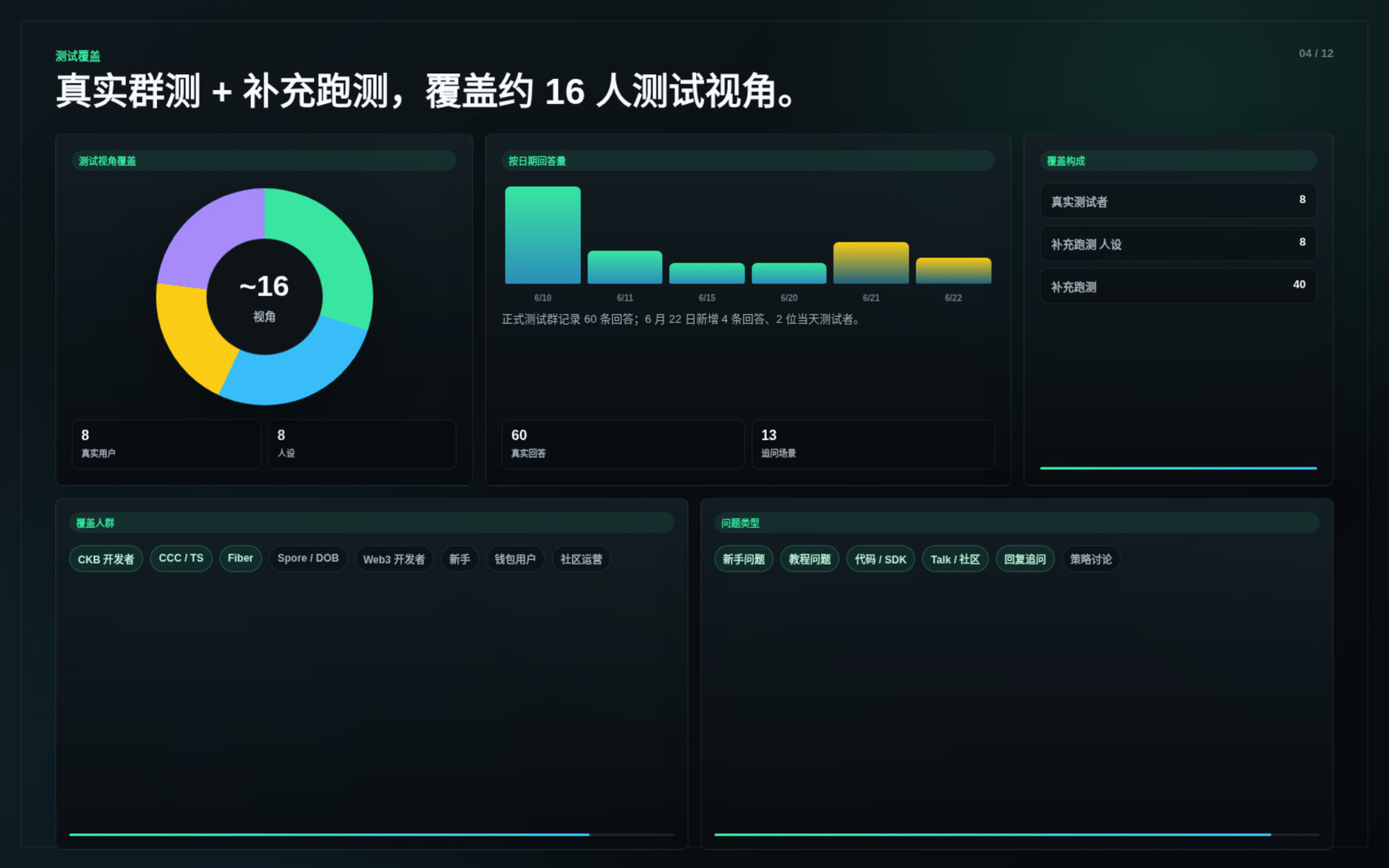
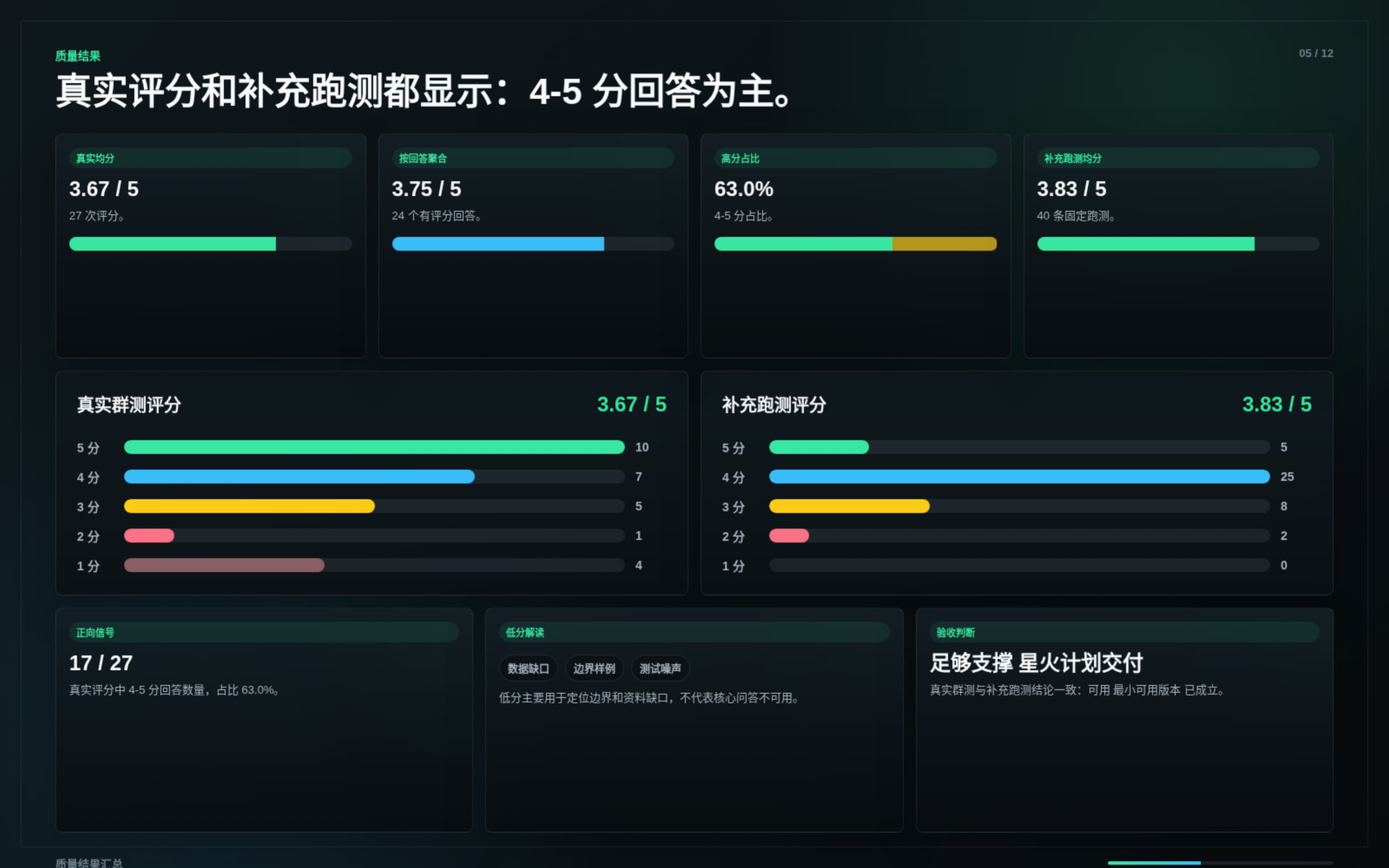
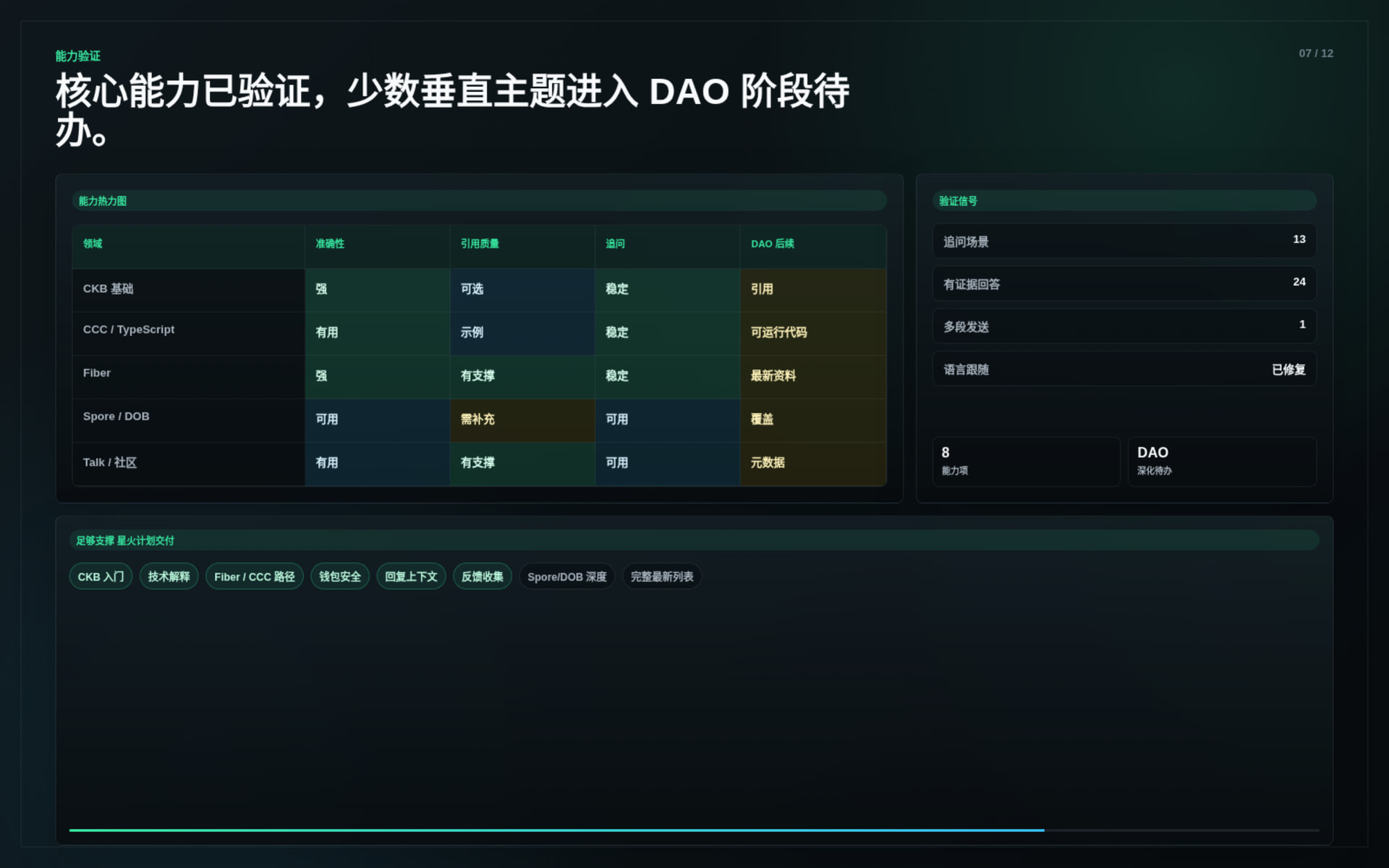
The system was tested through real community usage and supplemental evaluation runs.
Key results:
The tests covered:
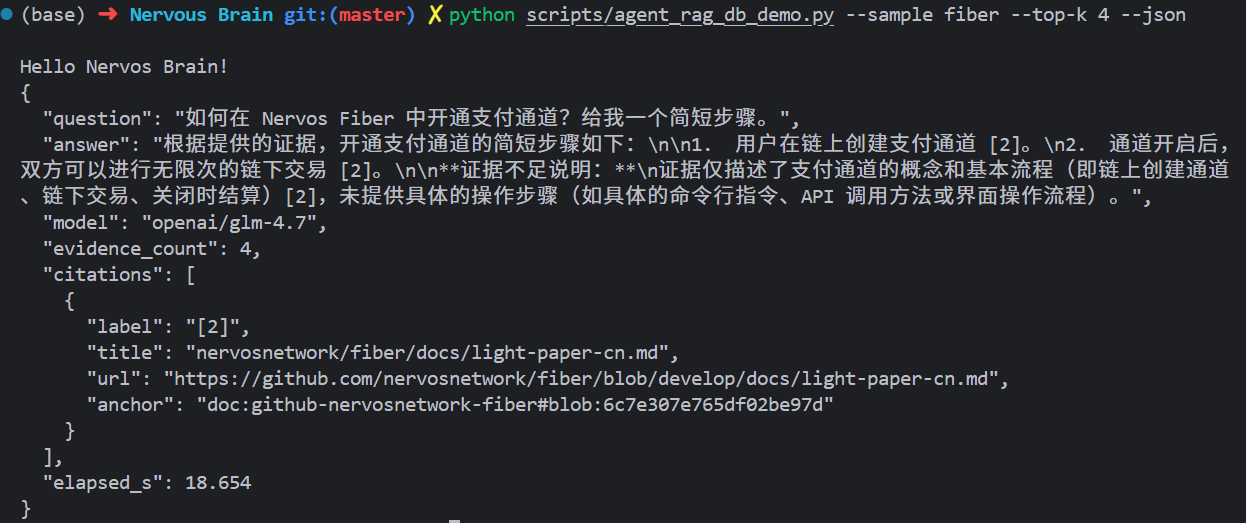
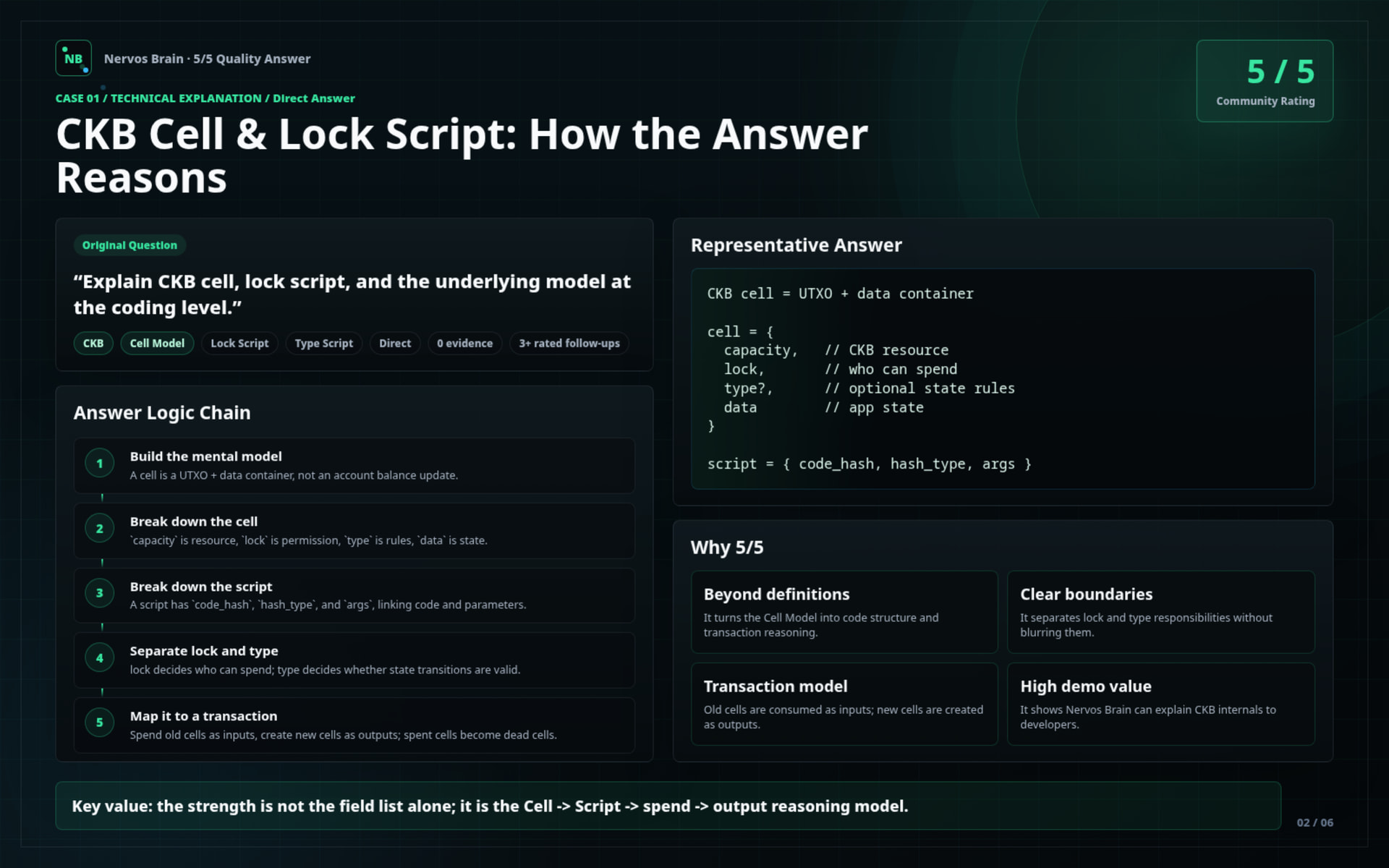
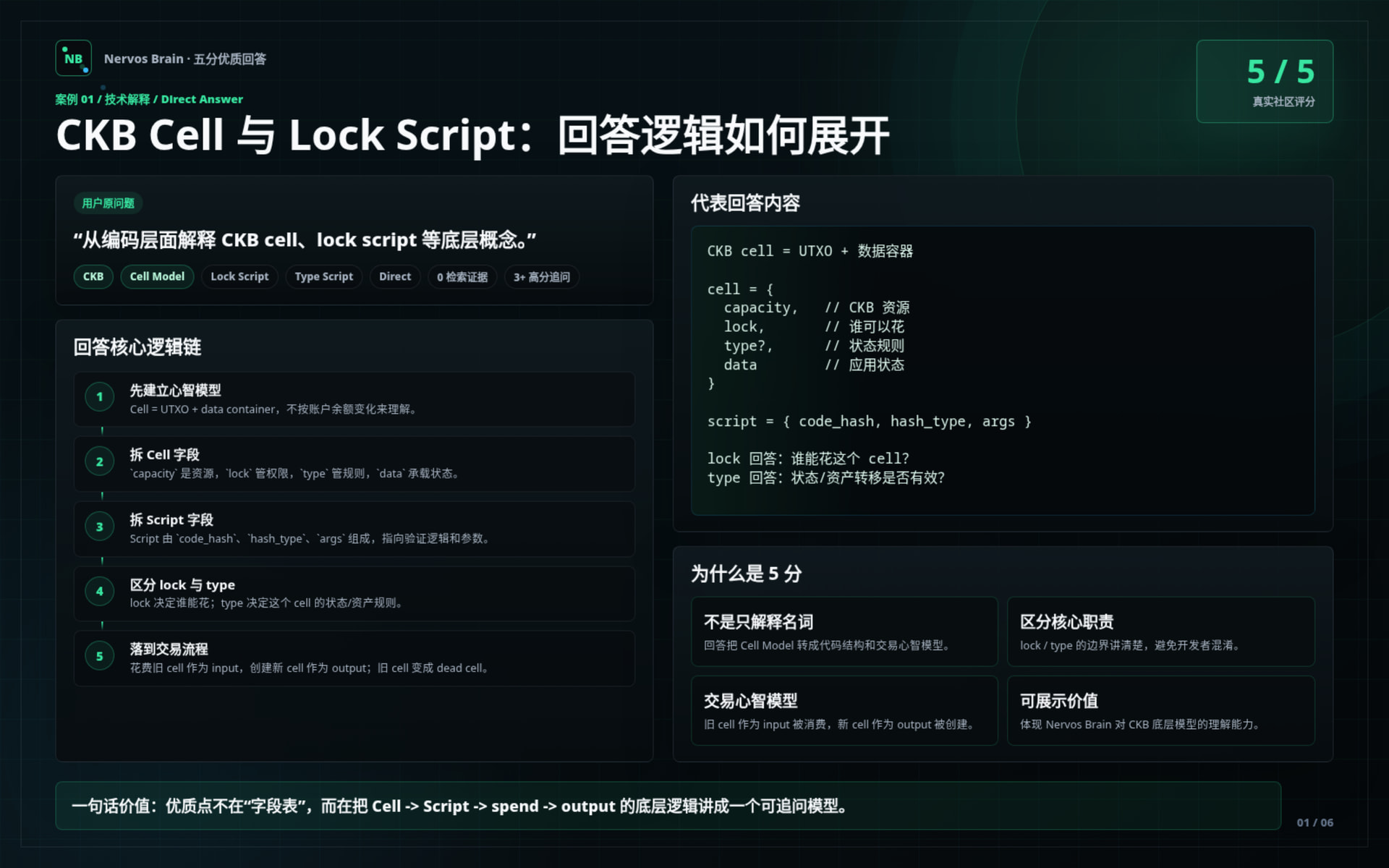
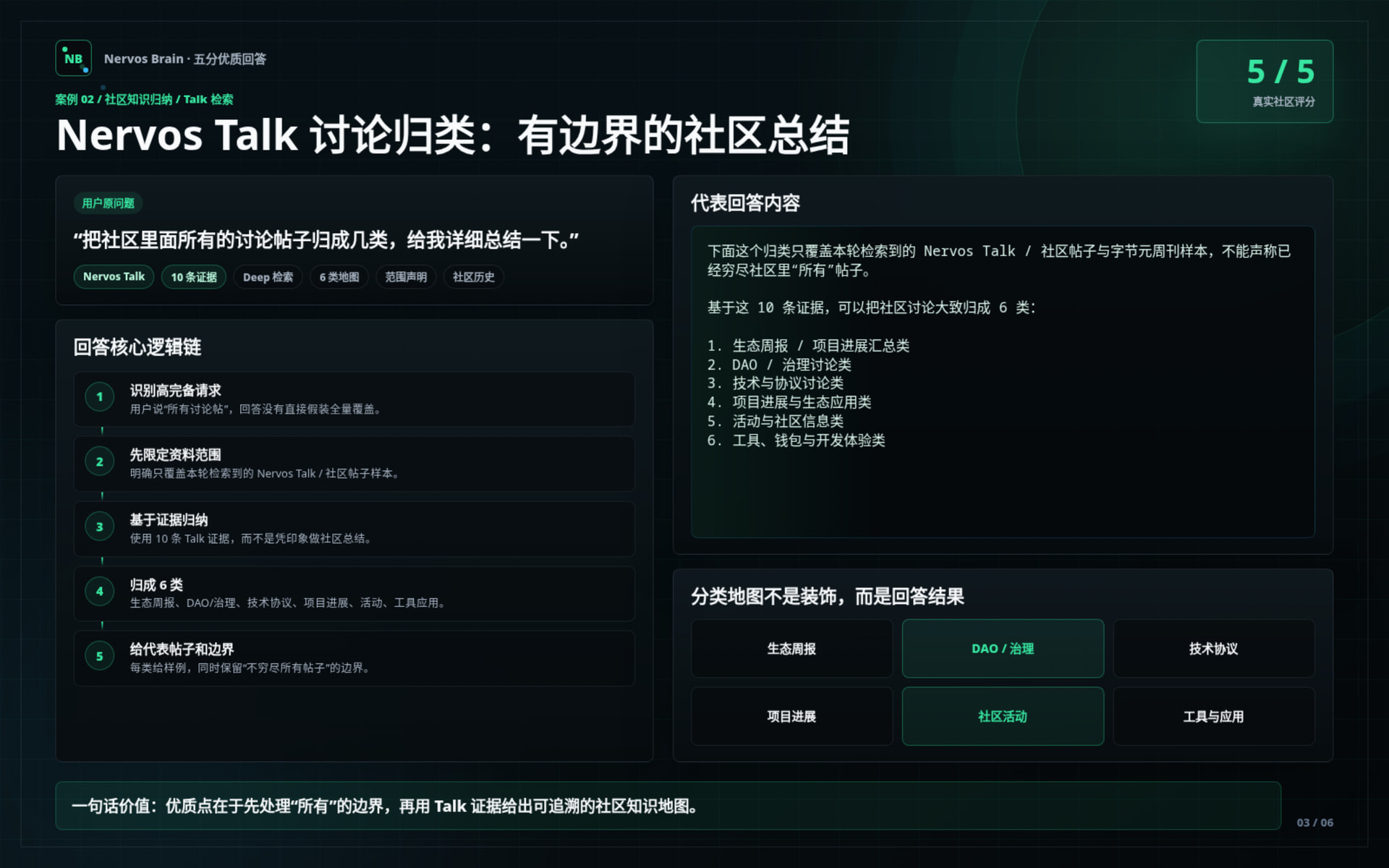
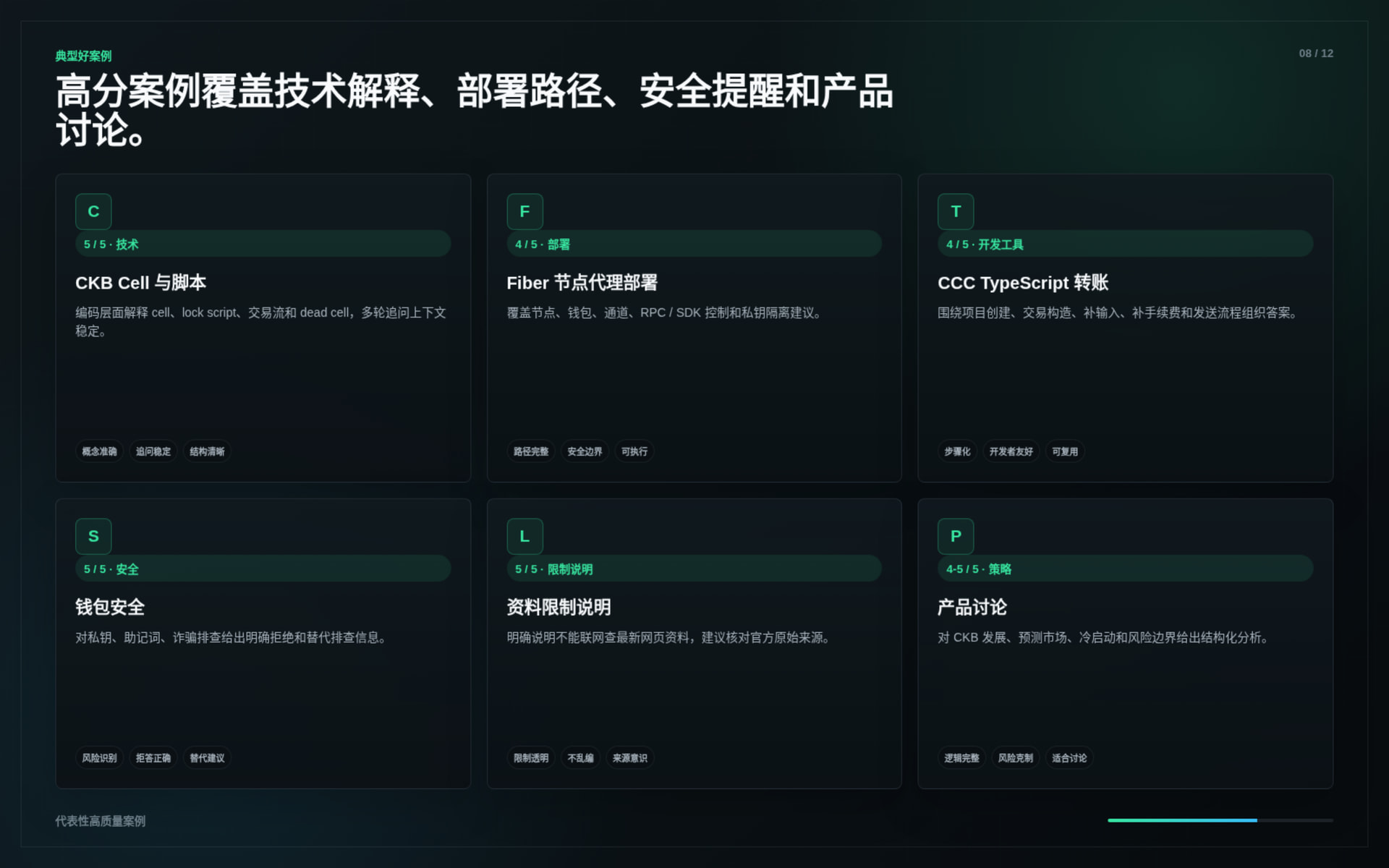
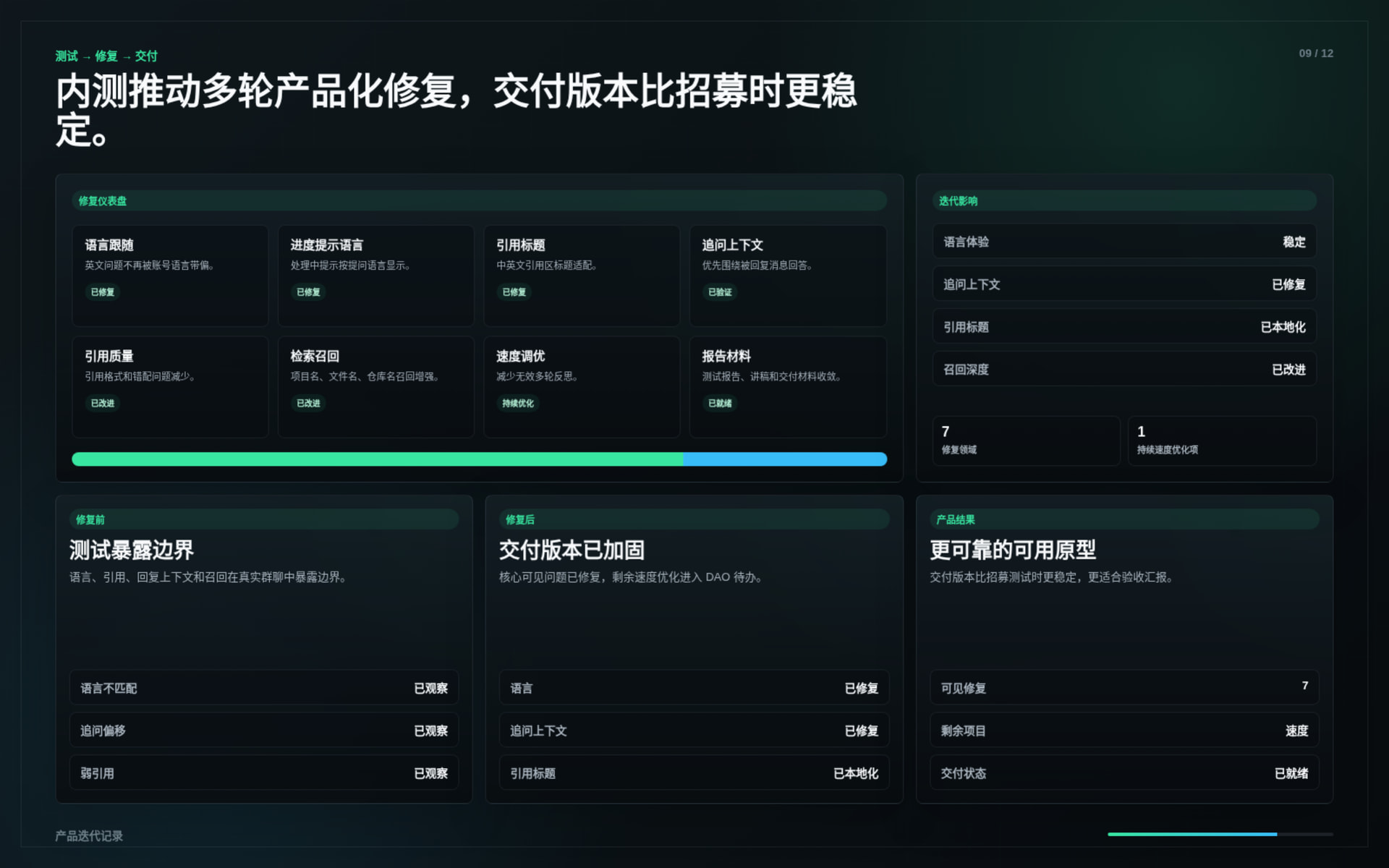
The first group of images shows selected high-quality answers from the test phase.
These cards are structured to show not only what the answer said, but why the answer was useful:
Selected cases include:
CKB Cell & Lock Script explanation
Demonstrates how Nervos Brain explains CKB’s Cell Model from a developer mental model, including cell fields, lock script, type script, and transaction input/output flow.
Nervos Talk discussion mapping
Demonstrates how Nervos Brain summarizes community discussions with a clear retrieval boundary instead of pretending to cover all historical posts exhaustively.
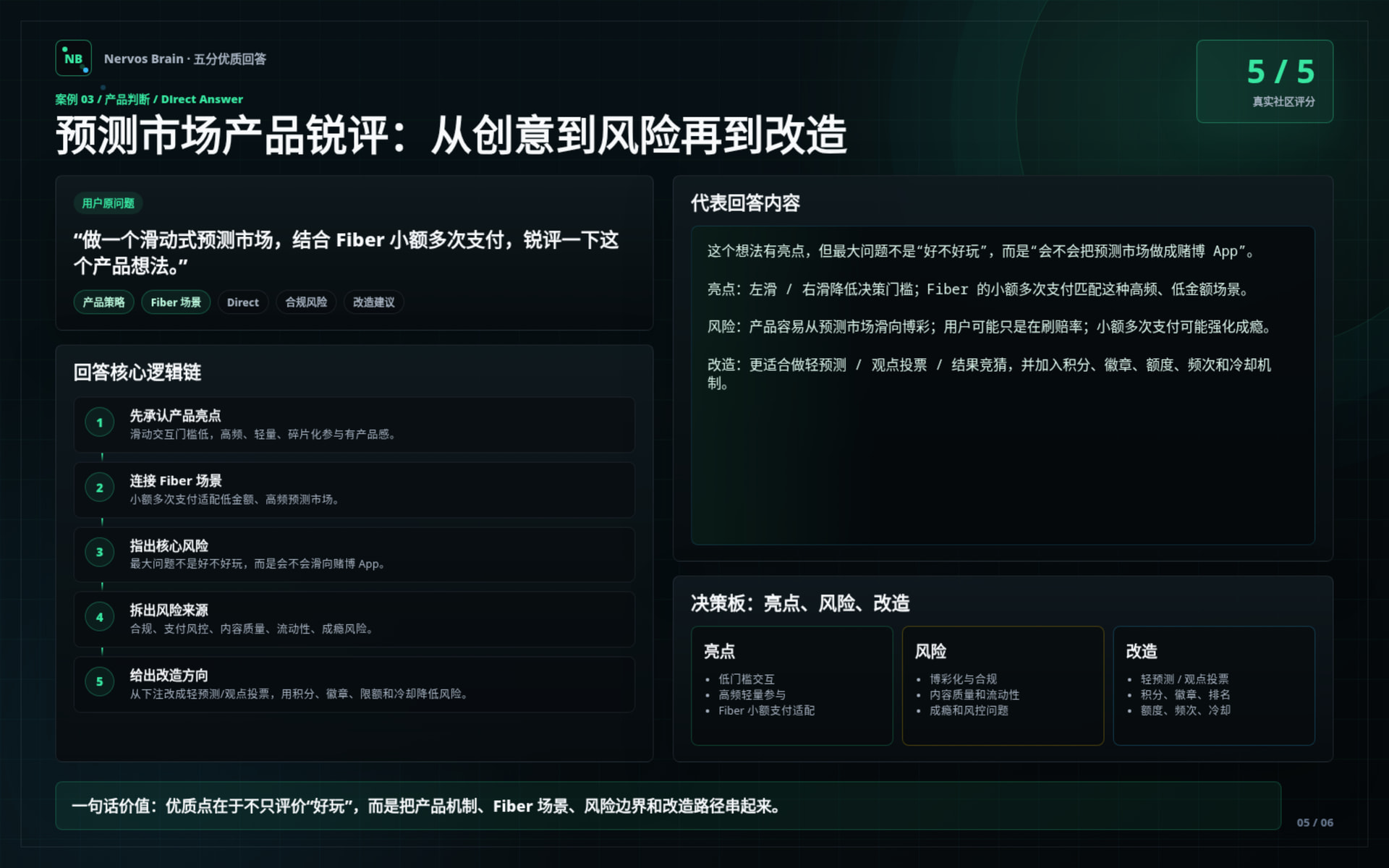
Prediction market product review
Demonstrates how Nervos Brain can evaluate a product idea by connecting Fiber’s small-payment use case with product risks and safer design alternatives.
The following images are the English delivery deck.
It summarizes:
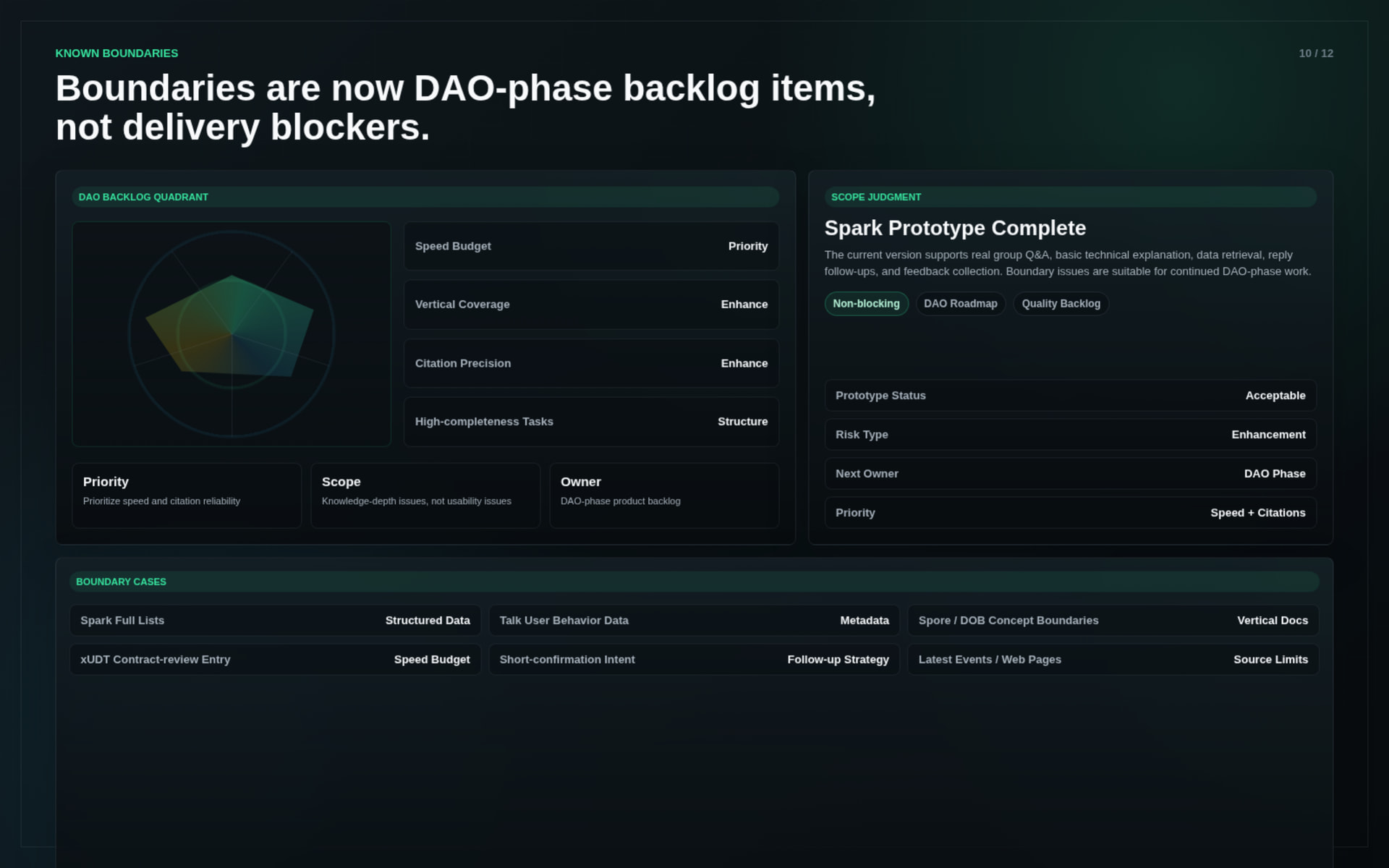
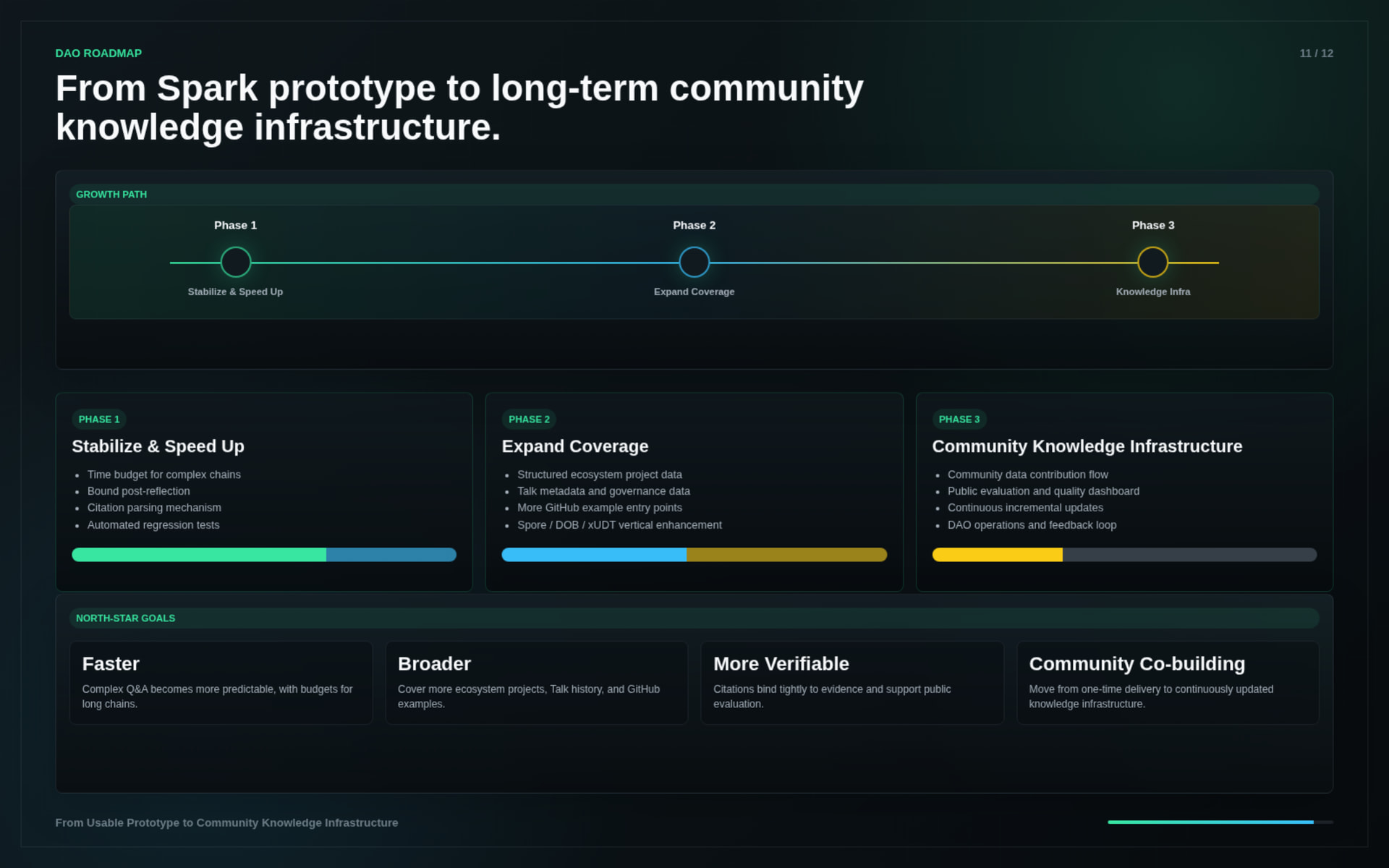
The Spark Program delivery validates the core direction and demonstrates the first working version of Nervos Brain. However, this is still the foundation layer, not the final form.
Current limitations include:
These are not blockers for the Spark Program delivery. They define the next stage: moving from a knowledge assistant toward a more autonomous Nervos intelligence layer.
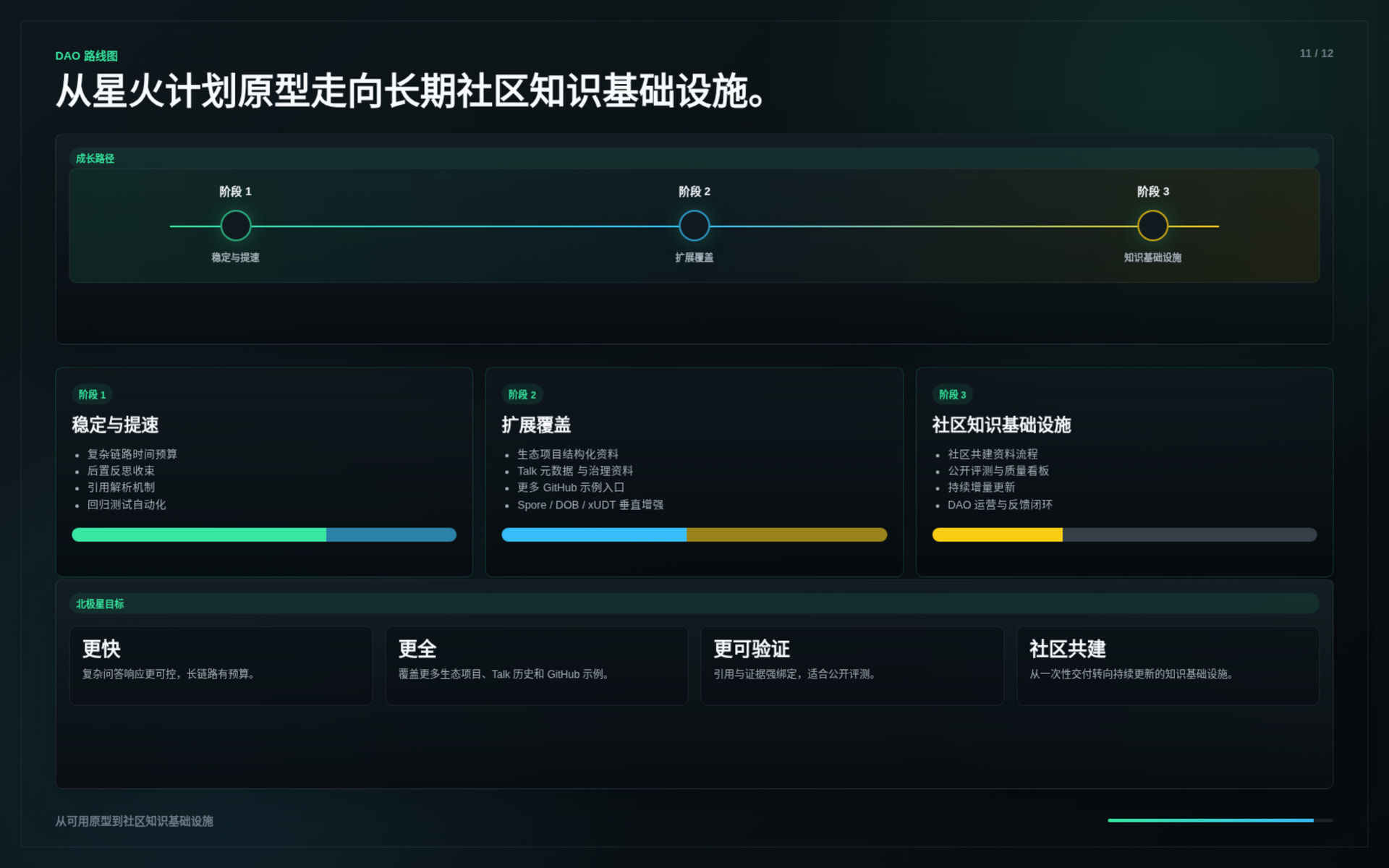
The DAO stage should not be limited to “making the bot better.”
The larger direction is to evolve Nervos Brain from an Agentic RAG knowledge system into an autonomous developer onboarding and ecosystem intelligence engine for Nervos.
In the Spark Program stage, Nervos Brain proves that it can understand questions, retrieve ecosystem knowledge, generate structured answers, cite sources, handle follow-ups, and collect feedback.
In the DAO stage, the goal is to move toward a more autonomous system:
Longer term, Nervos Brain can become more than a Q&A interface. It can become an embodied intelligence interface for the Nervos ecosystem.
Here, “embodied” does not mean a physical robot. It means the intelligence is no longer isolated inside a text box. It can be embodied through real ecosystem interfaces:
This would allow Nervos Brain to gradually evolve from answering questions to assisting real workflows.
Possible DAO-stage directions include:
Autonomous Knowledge Maintenance
Automatically track changes across Nervos documentation, Talk discussions, GitHub repositories, and ecosystem updates, then refresh the retrieval layer and surface important changes.
Developer Onboarding Agent
Guide new developers from “What is CKB?” to concrete learning paths, runnable examples, SDK usage, deployment steps, and project-specific recommendations.
Cross-Language Knowledge Bridge
Reduce the gap between Chinese and English ecosystem knowledge by organizing, translating, summarizing, and aligning important discussions and technical materials.
Ecosystem Intelligence Dashboard
Turn community questions, ratings, failed answers, missing sources, and recurring topics into structured signals for ecosystem improvement.
Tool-Using Agent Layer
Extend Nervos Brain from passive retrieval to controlled tool use, such as checking repositories, reading forum topics, generating reports, and assisting maintainers with structured tasks.
Human-in-the-loop Autonomous System
Keep critical actions reviewable by project maintainers while allowing the system to autonomously collect evidence, draft answers, identify gaps, and propose updates.
Autonomous Builder Agent with Coding-Agent Integration
A more ambitious DAO-stage direction is to make Nervos Brain a higher-level autonomous builder agent for the Nervos ecosystem.
In this model, Nervos Brain would not only answer questions. It would understand developer goals, break them into engineering tasks, retrieve the relevant Nervos knowledge, and coordinate coding agents such as Codex to execute implementation work.
For example, a developer could ask:
Nervos Brain would act as the higher-level planner and domain intelligence layer:
This creates a layered agent architecture:
Nervos Brain = domain planner + ecosystem memory + evaluator
Codex / coding agent = implementation executor
The long-term vision is that Nervos Brain becomes the upper-level Nervos intelligence coordinator. It can guide developer onboarding, answer questions, generate code examples, maintain documentation, open structured improvement tasks, and coordinate coding agents to build actual artifacts.
This would move Nervos Brain from:
Q&A system → onboarding engine → autonomous ecosystem assistant → Nervos builder agent
In this direction, Nervos Brain can become a practical bridge between ecosystem knowledge and real developer output.
The Spark Program version proves that Nervos Brain can already support real Nervos / CKB onboarding, technical Q&A, cross-language explanation, source-based retrieval, and measurable feedback.
The DAO stage would turn Nervos Brain into a longer-term Nervos intelligence infrastructure project: a global onboarding engine, cross-language knowledge hub, autonomous ecosystem assistant, and eventually a higher-level builder agent that can coordinate coding agents to produce real Nervos developer artifacts.