第二周周报
一、本周工作概述
本周主要围绕LangGraph 相关的核心内容展开,重点推进了工作流主干的搭建、Agent 动态路由逻辑设计以及多工具调用链路的组织。同时,结合上周周报中的计划,补充完成了数据库最小实现准备工作,为后续真实数据接入和检索闭环奠定基础。
二、本周完成内容
1. LangGraph 核心引擎搭建
本周完成了面向真实执行流程的 LangGraph 主框架搭建,初步形成了从用户问题进入系统,到信息分析、检索规划、结果生成的基本执行骨架。相比前期的 Mock/Print 脚手架阶段,目前图结构已经具备了实际的流程编排能力,能够支撑后续节点逐步替换为真实逻辑。
2. Agent 动态路由逻辑设计与实现
在主图骨架基础上,本周重点实现了基于状态判断的动态路由机制。系统能够根据当前问题是否缺失必要信息、是否需要继续检索,以及结果是否可直接进入回答阶段,动态决定下一步执行节点。整体流程如下:
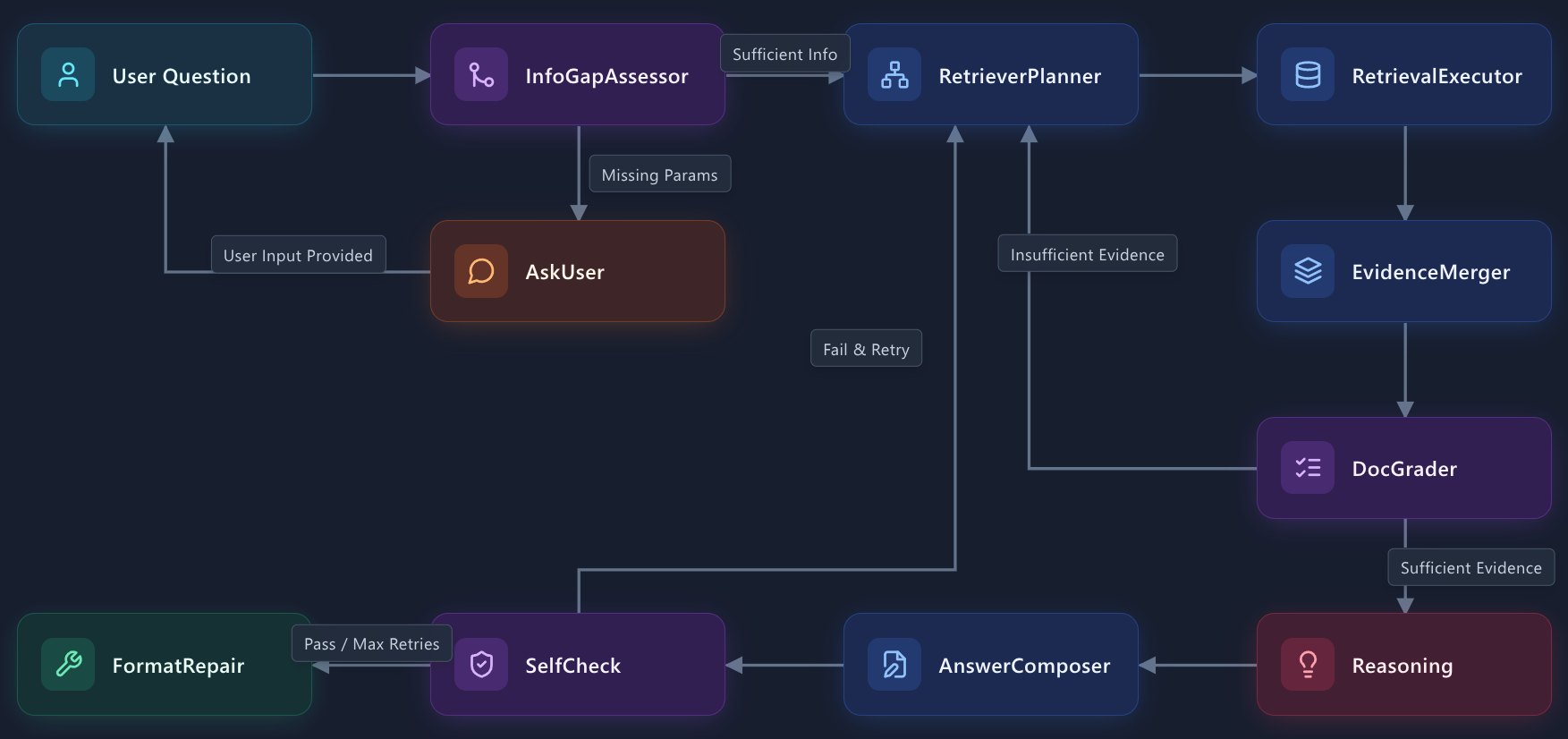
该部分的完成,使工作流具备了更接近 Agent 的最小决策能力,不再是固定顺序执行,而是能够根据状态在不同分支之间切换。
3. 多工具调用逻辑初步打通
本周完成了图工作流与多工具调用逻辑的初步串接。当前已经能够在检索执行阶段根据计划组织工具调用,并将返回结果统一汇入后续证据处理节点。这样一来,LangGraph 中的节点不仅承担流程控制作用,也开始承担工具调度职责,为后续扩展更多真实工具接口提供了统一入口。
4. 数据库相关最小实现准备
结合上周计划,本周同步补充了数据库侧的基础工作,主要包括:
- 对记忆与状态持久化相关的数据结构进行了最小落地;
- 对后续检索所依赖的数据组织形式进行了梳理;
- 为后续真实数据入库、检索与状态恢复保留了接口和结构基础。
当前这部分仍以“最小可用准备”为主,重点在于支撑后续真实数据链路,而不是一次性完成完整数据库能力建设。
三、本周阶段性成果
截至本周,项目在工作流层面已经从“流程演示型脚手架”推进到“具备动态路由能力的最小执行图”阶段。与此同时,数据库相关的基础结构也已开始落地,为后续接入真实数据、形成完整检索闭环打下了基础。
四、存在问题
目前 LangGraph 主链路已经搭建完成,但由于真实数据仍未充分接入,当前工作流更多体现的是“执行框架已成型”,而非“真实数据驱动下的稳定效果验证”。数据库部分也仍处于基础准备阶段,后续还需要继续围绕数据获取与入库链路推进。
五、下周计划
下周工作将暂时不再扩展 LangGraph 的鲁棒性和节点优化,重点转向数据获取和数据库构建,优先推进后续真实检索链路所依赖的数据基础。具体计划如下:
-
推进数据获取工作
围绕项目后续检索需求,继续整理和获取首批可用语料,明确不同数据来源的接入方式、字段结构和最小可用范围,为后续统一入库做准备。 -
推进数据库构建工作
重点完善数据库相关基础设施,包括向量库与记忆库所需的数据结构、最小入库格式以及基础建库流程,逐步形成可支持检索与状态存储的底层数据环境。 -
打通“数据获取 → 数据入库”最小链路
在获取数据和数据库结构基本明确后,优先尝试跑通一条最小闭环,使部分真实数据能够完成清洗、组织并进入数据库,为后续工作流接入真实数据做好准备。
Weekly Report: Week 2
1. Work Overview
This week’s work primarily centered around the core components of LangGraph. We focused on advancing the construction of the workflow backbone, designing the Agent’s dynamic routing logic, and organizing the multi-tool invocation pipeline. Meanwhile, in alignment with the plan from last week’s report, we completed the preparatory work for the minimal implementation of the database, laying the foundation for the future integration of real data and achieving a closed-loop retrieval system.
2. Completed Work
2.1 Construction of the LangGraph Core Engine
This week, we completed the construction of the main LangGraph framework tailored for real execution workflows. We have established a basic execution skeleton covering the entire process: from receiving user queries, analyzing information, and planning retrieval, to generating results. Compared to the previous Mock/Print scaffolding phase, the current graph structure now possesses actual process orchestration capabilities, enabling the gradual replacement of subsequent nodes with real logic.
2.2 Design and Implementation of Agent Dynamic Routing Logic
Building upon the main graph skeleton, this week we focused on implementing a dynamic routing mechanism based on state evaluation. The system can dynamically determine the next execution node based on whether the current query lacks necessary information, whether further retrieval is needed, and whether the results are ready for the answering phase. The overall flow is as follows:
The completion of this module endows the workflow with minimal decision-making capabilities, making it closer to a true Agent. Instead of executing in a fixed, sequential order, it can now switch between different branches based on its state.
2.3 Initial Integration of Multi-Tool Invocation Logic
This week, we achieved the initial integration of the graph workflow with the multi-tool invocation logic. Currently, during the retrieval execution phase, we can organize tool invocations according to the plan and uniformly route the returned results to subsequent evidence processing nodes. Consequently, the nodes in LangGraph now not only handle process control but also assume the responsibility of tool orchestration, providing a unified entry point for expanding more real tool interfaces in the future.
2.4 Preparation for Database Minimal Implementation
In conjunction with last week’s plan, we synchronously supplemented foundational work on the database side, mainly including:
- Performing a minimal implementation of data structures related to memory and state persistence;
- Outlining the data organization formats required for future retrievals;
- Reserving interfaces and structural foundations for subsequent real data ingestion, retrieval, and state restoration.
Currently, this part remains focused on “minimum viable preparation,” with an emphasis on supporting the upcoming real data pipeline rather than building out complete database capabilities all at once.
3. Milestone Achievements of the Week
As of this week, at the workflow level, the project has advanced from a “process demonstration scaffold” to a “minimum execution graph with dynamic routing capabilities.” At the same time, the fundamental database structure has begun to take shape, laying the groundwork for integrating real data and forming a complete closed-loop retrieval system.
4. Current Challenges
Although the main LangGraph pipeline has been constructed, real data has not yet been fully integrated. Therefore, the current workflow primarily reflects that “the execution framework is shaped,” rather than representing “stable performance validation driven by real data.” The database component is also still in the basic preparation stage, and further progress is needed regarding the data acquisition and ingestion pipeline.
5. Plan for Next Week
Next week, we will temporarily pause the expansion of LangGraph’s robustness and node optimization. Instead, the focus will shift to data acquisition and database construction, prioritizing the data foundation required for the subsequent real retrieval pipeline. The specific plans are as follows:
- Advance Data Acquisition
Centered around the project’s future retrieval needs, we will continue to organize and acquire the first batch of usable corpus. We will clarify the integration methods, field structures, and minimum usable scope for different data sources to prepare for unified data ingestion. - Advance Database Construction
We will focus on improving database-related infrastructure, including the data structures required for the vector database and memory store, the minimal ingestion formats, and the basic database creation process. This will gradually form an underlying data environment capable of supporting retrieval and state storage. - Integrate the Minimal Pipeline from “Data Acquisition” to “Data Ingestion”
Once the data to be acquired and the database structure are fundamentally defined, we will prioritize running a minimal closed loop. This will enable a portion of real data to be cleaned, organized, and ingested into the database, paving the way for the workflow to integrate real data in subsequent phases.