How to obtain the current block number
I have heard developers repeatedly complain about why they can’t read the current block number in their CKB scripts(smart contract)?
As every blockchain developer knows, reading the current block number from a smart contract is a fundamental feature of Ethereum and other blockchains that use EVM. So if CKB, like it says, is the next-generation blockchain, why can’t it accomplish things that the previous generation blockchain could?
Well, I guess few people can answer it, the core team hasn’t explained the unique design of CKB to the community frequently, which I think the core team should do better.
So I decided to write this article to explain the trade-off of this design: why can’t we read the current block number in the script.
The right way
Let’s start by examining the right way to read the block number in the CKB script.
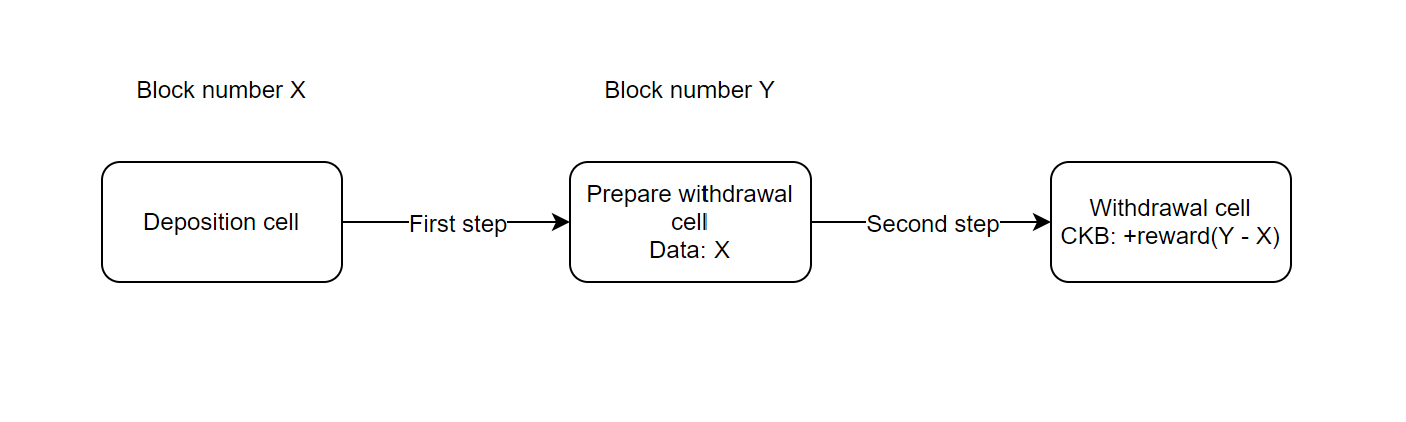
By my observation, most developers ask for the block number to measure the block time between two actions, in abstract terms: a user deposits at block height X then withdraws at block height Y. After the withdrawal, the smart contract has to calculate the blocks during X to Y, and send a reward to the user according to the user’s deposit time or do other things similar.
Ethereum can read the block number of the current block directly and calculate the reward. In CKB, however, instead of reading the block number, we must employ alternative approaches:
- We can constrain the withdrawal transactions by using the transaction valid since feature to ensure that no withdrawal transaction takes place until the deposit has been completed at least after Z blocks. However, the user can delay the tx for a longer time than Z, which may not be appropriate in some situations.
- We can use a two-step withdrawal to locate the block height. Step one, we read the deposition block height X by using CKB syscalls, then record the X in the new prepare-withdrawal cell; step two, we use syscall to read the height of the prepare-withdrawal cell Y and read the X from the cell’s data. Thus, we can calculate the block time Y - X.
The off-chain determinism
So what’s the purpose of doing this? Obviously, developers prefer the simpler and more intuitive method, so why does the CKB use such a difficult method to do a simple job?
It is all about the off-chain determinism. Let’s start by explaining two questions: What is the input of the Ethereum contract? What is the input of the CKB script?
If we consider the contract(or script) as a function f, then we can represent the smart contract’s calculation in the following form:
In Ethereum:
output = f(tx, state tree, current blockchain)
In CKB:
output = f(tx, deterministic blockchain)
In Ethereum, a contract can retrieve information from three inputs: tx, the account state tree, and the current blockchain status. For example, a smart contract can read current block number and block hash from blockchain.
In CKB, we only allow a script to read deterministic inputs. If a user wants to read information from the blockchain, the user must include the block’s hash in the tx in the first place. Thus, all information that a script can read is deterministic. We called it off-chain determinism, which is a fundamental feature of CKB.
The advantages
Off-chain determinism brings some benefits, the most important one is that once we verify a tx, we know the tx will always be valid or invalid since it is deterministic. The verification result doesn’t depend on blockchain status.
The determinism introduces a verification strategy in the CKB, in which we only verify a tx once before pushing it into the memory pool. When we package txs into a block, we only need to check the tx inputs are still unspent; this cost is tiny compared to doing a complete verification for a tx.
This off-chain determinism of tx is not only bound to one node; We can guarantee that a tx is valid even if we send it across the P2P network. Because a tx, if valid, will remain valid permanently, so the CKB only broadcasts valid txs to other nodes. If a malicious node tries to broadcast invalid txs, network peers will immediately ban it once they fail to validate a tx sent by the malicious node. As invalid txs can’t get broadcast into the CKB network, the CKB only packages valid txs into blocks, which I think is a major advantage of CKB.
Note that it is infeasible in Ethereum because Ethereum tx is not off-chain determinism, a tx may fail on block number 42 even if it is valid on block number 41. Thus, we never know whether a failed tx was sent intentionally by a malicious peer or failed because the blockchain tip state changed. Thus, Ethereum chooses another way, where Ethereum allows nodes to broadcast invalid txs and package them into the block. The protocol then enables miners to peanalize failed txs by charging the maximum fee from the sender’s account. This mechanism aims to enhance security by incentivizing users to send only valid txs; even if you are an honest user, you may send a failed tx by accidentally running into an invalid contract state. (I have lost about 50$ in a failed tx when I tried to deposit into Curve.)
Whether to include only valid txs in the block or include failed txs in the block then to penalize the sender, such different design philosophies come from different answers to the simple question: should we allow a script to read the current block number?
Layer1 robustness vs. user experience
From what I understood, between the layer1 robustness and the user experience, the design of CKB clearly chose the former.
And I believe this is a correct choice; the only important thing of the layer1 blockchain is to provide robustness and secured service. And this trade-off doesn’t mean that CKB has no concern for users’ experience. Remember the slogan of CKB: a layer1 built for layer2. And in this case, layer1 is made for robustness, and layer2 is made for user experience.
In layered architectures, most people would use a higher-layer technique, only a few people need to access from the lower-layer. For example, most users use HTTP or WebSocket; less people use TCP or UDP, and almost no one uses IP directly.
From a smart contract developers’ perspective, you might find this design incomprehensible; but if you look at the layered architecture, the design is a natural fit for the layer1 blockchain.
Once the layer2 facility is launched, developers will be able to access the features provided by layer 2 comfortably, not only for reading block numbers (which is simple) but also for more powerful features ( leaving room for the developer’s own imagination).