引言
这篇文章是此前发布的《当 84% 的开发者都在用 AI Coding,CKB 开发者体验的下一步怎么走?(附完整调研与路线图)》的延续。上篇报告揭示了 CKB 生态在 AI 可发现性上的系统性缺口,核心问题之一是:CCC 文档匮乏,导致 AI 工具在回答 CKB 相关问题时难以获取准确信息。
本文记录了过去一个多月以来,我们从零建设 docs.ckbccc.com 的完整过程——包括选型决策、内容迭代、DeepWiki 辅助 review 的经验与教训、35 个文档页面的编写和汉化工作流,以及 GA 埋点基础设施的准备。
一、为什么要专门建一个 CCC 文档站?
建站之前,CCC 的"文档"分散在三个地方:README 里有基础介绍、TypeDoc 生成的 API 参考,以及CCC的 Demo 示例。但没有一个地方能让开发者找到"从零开始如何用 CCC 做 X"这类完整答案。
当时 CCC 整个文档站的全部内容非常简陋,只有四个介绍性的页面:
这四个页面涵盖的内容极为有限,既没有 Getting Started,也没有各包的详细说明,更没有任何面向具体开发场景的指南。
更关键的问题在于 AI 可发现性。上篇报告提到:viem(Ethereum 的 TypeScript 接口库,功能定位与 CCC 类似)在 Context7 上有 5800+ 个代码片段,而 CCC 只有 141 个,差距达 41 倍。这意味着开发者用 Cursor 或 Claude Code 写 CKB 相关代码时,AI 几乎找不到有效的参考材料,要么给出过时的答案,要么直接产生幻觉。
建立一个结构化的文档站,是解决这个问题最直接的切入点。
二、技术选型:DeepWiki、Mintlify 还是自建?
在动手之前,我们对市面上的文档工具做了一轮选型调研,大致分为三类:
- 自动生成型(DeepWiki)
- 托管平台型(Mintlify)
- 开源自建型(Fumadocs、Docusaurus 等)
它们的核心差异不只是部署方式,更在于 AI 时代需要同时服务好两类读者:人类开发者和 AI Agent(ChatGPT、Claude、Cursor、Devin 等)。
1. DeepWiki:适合辅助的代码导览
DeepWiki 能直接分析 GitHub 仓库,自动生成架构说明、模块关系与项目 Wiki,并支持基于代码库的问答。对初次接触项目的开发者,这能降低理解代码结构的门槛。
但它的内容主要来自代码,定位更接近“代码导览层”,不适合作为官方知识库的唯一载体,原因在于:
- 内容由 AI 自动生成,结构和表达方式不可完全控制;
- 设计理念、最佳实践、迁移指南等知识无法仅从代码中推导;
- 自动生成存在一定的幻觉风险,需要人工校验;
- 无法承载社区长期沉淀的经验和背景知识。
对 SDK 项目而言,开发者真正需要的往往不只是“代码是什么”,更是:为什么这样设计、推荐怎样使用、完整的教程指南、常见错误如何避免——这些知识更多积累在设计文档、Issue、PR 讨论和社区经验中,而非代码本身。因此,DeepWiki 是一个很好的辅助入口,但不适合作为官方文档的唯一载体。
2. Mintlify:优秀的文档 SaaS,但长期存在制约
Mintlify 是目前最受欢迎的开发者文档托管平台之一,提供精美的默认 UI、AI 问答、MCP 集成等现代能力,适合快速上线文档的团队。然而,对于希望长期运营的开源项目,我们更关注以下问题:
- 品牌控制权文档站不仅是知识库,还会逐步演变为项目官网、开发者门户、教程与生态入口。这要求团队对首页、导航、布局、组件和交互拥有完全控制权,而 SaaS 平台难以做到这一点。
- 平台依赖虽然文档内容存储在 Git 仓库中,但搜索、组件体系、主题系统以及部分高级能力仍依赖平台本身。从长期看,我们希望核心基础设施掌握在社区手中,而不是绑定在单一商业服务上。
- 长期可扩展性随着内容规模增长,文档站会逐渐需要多语言支持、Cookbook、Examples、RFC、MCP 文档、AI 专用索引、开发者数据分析等能力。此时,一个完全可控的技术栈会拥有更高的灵活性。
3. 自建方案:将文档视为项目基础设施
经过评估,我们最终选择了基于 Fumadocs 的自建方案,原因不只是为了降低成本,而是因为官方文档本身就是项目基础设施的一部分。
在 AI 时代,文档承担着双重职责:
- 面向人类开发者——帮助快速理解核心概念、API 使用方式、最佳实践和常见问题;
- 面向 AI Agent——帮助 AI 正确理解项目的能力边界、API 定义、示例代码和推荐使用模式,直接影响其生成代码与回答的准确性。
从这个角度看,文档已不仅是知识库,更是项目面向 AI 世界的标准接口。
最终技术栈
我们采用 Fumadocs + Next.js + GitHub 的自建方案:
- **Fumadocs 作为文档框架:**完全开源(11k+ stars,160+ contributors),不依赖商业服务;对
llms.txt有原生支持——框架搭好、第一个文档编译通过后,访问/llms.txt即可看到自动生成的文档索引,无需额外配置。 - **Next.js 作为运行时:**更好的 SEO 资产沉淀能力。
- **GitHub 作为内容源:**确保内容与社区协作完全自主可控。
收益与投入
相比 SaaS 平台,该方案需要更多工程工作,但能够获得:
- 完整的内容所有权
- 完整的品牌控制权
- 更好的 SEO 资产沉淀
- 面向 AI 的长期可扩展能力
对于一个希望长期维护和发展的开源 SDK 项目而言,我们认为这是更值得的投入。
三、内容从哪里来:把 Mintlify 当“内容生成器”用
确定使用 Fumadocs 自建后,首先要解决初始内容从哪来的问题——从零手写所有文档并不现实。我们的策略是:先借助 Mintlify 自动生成参考内容,再批量导出并移植到自建工程中。
1. 用 Mintlify 生成参考版本
我们将项目代码部署到 Mintlify,获得了第一份参考目录和初版文档。为评估生成的质量和稳定性,又用相同代码生成了另一个版本,两者对比可明显看出差异:
相同源代码,Mintlify 在不同时间生成的文档结构可能完全不同(所有 AI 自动生成类文档均存在此问题)。 经过对比,我们最终选定了版本一的目录和内容作为初始文档的基础。
2. 批量导出 Markdown 原文
一个实用技巧是:Mintlify 的每个文档页面,在 URL 末尾添加 .md 就能直接获取该页面的 Markdown 原文。例如,访问 https://mintlify.wiki/ckb-devrel/ccc/quickstart.md 即可下载对应的 Markdown 文件。我们用这个方法批量导出了全部文档内容,作为自建工程的第一版原材料。
3. 人工 Review 和 Merge
此前我们在 Mintlify 上对相同代码生成了两份文档,二者的内容页面并不完全一致。为了尽可能充实文档,我们对这两份内容进行了人工 review:将同一主题下的内容逐一比对,取长补短,把有价值的段落 merge 后整合到自建文档站点中。这一步虽耗时,但有效弥补了 AI 单次生成的遗漏,使初始内容更加扎实。
4. 迁移中的两类兼容问题
将导出的内容放入 Fumadocs 项目时,需要解决以下问题:
-
文件头部说明需清理Mintlify 生成的 Markdown 文件顶部含有一段类似“这是文档索引,请先访问 llms.txt 获取完整目录”的说明,这些内容在 Fumadocs 中会导致编译报错,需要逐文件手动删除。
-
Mintlify 自定义组件不兼容Mintlify 使用一套专用 JSX 组件(如
<Note>、<CodeGroup>、<Tip>等),直接放进 Fumadocs 会编译失败。我们没有引入 Mintlify 的组件库(那样会带来大量样式覆盖),而是逐页将这些组件替换为 Fumadocs 提供的等效组件,例如<Callout>、<Tabs>等。

5. 完成初始内容框架
经过上述步骤,我们成功完成了自建文档的初始内容框架搭建,为后续的持续迭代奠定了基础。
四、多语言支持:默认没有,需要手动接入
我们希望文档同时支持中英文,但 Fumadocs 的项目模板默认不带多语言能力,需要额外配置。建议项目搭建起来的时候就支持上,之后扩展更方便。
另一个容易忽略的坑在于中文搜索。Fumadocs 内置搜索基于 Orama,默认对英文分词支持良好,但中文必须额外接入 @orama/tokenizers 并完成配置,否则中文关键词会无结果。这些配置在 Fumadocs 官方文档中都能找到。
还有一个值得留意的点是多语言文档的目录组织方式。常见做法有两种:一种是按语言拆分独立目录,每个语言各自维护一套完整的文档树;另一种是保持统一的目录结构,不同语言通过文件后缀区分。CCC 文档采用的是后者——默认语言为英文,例如 getting-started/ 目录下,英文文档为 installation.mdx,对应的中文版本为 installation.zh.mdx,两者并排存放在同一个文件夹中。这样做的好处是,在编辑器里一眼就能看出哪些文档已有翻译、哪些还缺失;而如果按语言拆分目录,修改内容时需要在两棵目录树之间来回切换,很容易漏改某一侧的文件。
五、用 DeepWiki 做文档 review:有用,但要保持批判性
在翻译中文文档之前,我们先做了一件事:用 DeepWiki 对所有英文文档逐篇 review,确保内容与最新代码一致。
为什么先 review 再翻译?
如果英文文档存在错误,等到翻译完中文才发现,就需要中英两份文档同时修改,造成返工。先保证英文准确性,可以避免重复劳动。
操作流程:
- 在 DeepWiki 上将 CCC 仓库同步至最新版本,确保 review 基于最新代码而非旧快照;
- 逐篇把文档内容发给 DeepWiki,让它对照代码库进行勘误;
- 人工审核 DeepWiki 的结论,并点击其引用的代码片段链接进行二次确认。
这个流程整体有效,但有一点需要警惕:DeepWiki 有时会犯错,而且犯错时态度非常自信。 我们遇到了两个典型案例。
案例一:误判方法不存在(useSigner)
在 review @ckb-ccc/connector-react 的文档时,DeepWiki 指出文档中描述的 useSigner hook 不存在于代码库中,建议删除:

但实际上 useSigner 是真实存在的——它位于 packages/connector-react/src/hooks/useSigner.tsx,是对 useCcc().signerInfo?.signer 的便捷封装。我们将实现代码贴给 DeepWiki 后,它随即承认错误,并确认文档描述准确无误:

案例二:混淆两个不同的方法名
在 review @ckb-ccc/core 文档时,DeepWiki 认为 tx.addCellDepInfos(client, deps) 方法名有误,建议改为 tx.addCellDepsOfKnownScripts(client, knownScript),并提供了代码引用作为“证据”:

实际上,这是两个不同的方法,都存在于 Transaction 类中:
addCellDepInfos接受通用的CellDepInfoLike参数;addCellDepsOfKnownScripts是接受KnownScript枚举的便捷方法。
文档中列出的方法名是正确的,DeepWiki 将两者混淆了。我们回复纠正后,DeepWiki 重新检查代码库并承认了错误。

经验:
- DeepWiki 作为文档 review 工具很有价值,能快速定位文档与代码之间的真实差异。但它的结论必须经过人工复核,尤其是当它声称“某物不存在”时,一定要先去代码里亲自确认一遍,再做定论。
- 可以开多个会话对相同文档分别进行Review,比对结果。
六、汉化工作:从“机翻稿”到“开发者会写的中文”
确认英文文档准确无误后开始翻译,共完成 35 个页面。
从错误中提炼规范
第一篇文档的翻译最费功夫。AI 初稿的典型问题包括:术语错误翻译(如 Cell 被译为“单元”、Signer 被译为“签名者”)、英文句式直译导致生硬、被动语态堆叠、复合名词词序不符合中文习惯(“签名消息”而非“消息签名”)等。
我们对第一篇文档做了逐行手动修改,然后将修改前后两个版本一起发给 Claude,要求它对比差异、提炼规律,输出一份专门针对 CKB 中文技术文档的翻译规范。将这份规范 zh-translation.md放到项目目录下,它涵盖:
- 专有名词处理规则(哪些必须保留英文,哪些首次出现时需附英文注释)
- 9 类常见机翻错误及正确写法(每条均附错误示例、正确示例和规则说明)
- 11 条“去翻译腔”规则(专门处理句式与结构问题,如超过 15 字的前置修饰语需拆句、结论提前等)
- 标点规范(全角破折号用法、行内代码空格、书名号禁用场景等)
- 语气与风格原则
- 两轮检查清单(第一轮查准确性,第二轮查翻译腔)
有了这份规范后,第二篇文档的翻译质量明显提升。此后每遇到规范未覆盖的新场景,就手动处理后更新规范。经过约 4–5 篇文档的迭代,规范基本稳定,后续翻译速度显著加快。
多工具交叉比对
我们没有只依赖单一 AI 完成翻译,而是让多个工具处理同一份文档,再交叉比对结果:
- Claude 桌面端:主力翻译工具,生成质量最高。
- Windsurf 内置 Claude:使用相同提示词作为对照组,生成质量略逊于桌面端。
- DeepSeek:用于 review Claude 的译文,检查是否符合
zh-translation.md规范,并提出额外优化建议。 - DeepWiki:尝试用于翻译,但表现不稳定——在会话中有时会忽略翻译指令,转而直接推荐自己的 Wiki 页面。

各工具输出的翻译版本,我们会放到 diffchecker.com 进行逐行对比,从中合并出更满意的版本。尤其在处理某些“怎么翻都不够好”的句子时,不同工具的译文往往各有亮点,对比之后常能拼出最优解。

几条实用经验
- 不要批量处理。 一次性提交大量文档,AI 翻译质量会明显下降。逐篇进行最稳妥。
- 会话过长 AI 会变钝。 在同一会话中连续翻译多篇后,AI 对早期规范的遵从度会逐渐降低。出现这种迹象时,新建一个会话并重新加载
zh-translation.md,效果会立刻恢复。 - 相同提示词多次运行也值得对比。 在 Claude 中用相同提示词对同一篇文档运行两次,两次结果会有差异,对比后往往能取长补短。
- 特别难处理的句子单独拎出来。 有些句子无论怎么翻译都不满意,不必在整篇翻译流程中反复纠缠。把该句子单独提出,问“这个句子读起来很别扭,有哪些调整方向”,让 AI 给出优化思路,再在不影响语意的条件下修改。例如
@ckb-ccc/spore文档中有一段描述 Spore 协议的长句,采用这一方法后,最终表达顺畅了许多。
七、GA 埋点:先把组件准备好
文档站的大部分内容就绪后,我们开始考虑如何了解站点的实际使用情况——比如各页面的访问量、代码块的复制点击次数、搜索关键词等数据,以此判断哪类内容对开发者最有价值。这需要接入 Google Analytics(GA4)。
这里面临一个结构性问题:Fumadocs 内置了代码块的复制按钮、搜索对话框等组件,如果直接使用这些内置组件,无法在点击事件中插入 GA 跟踪代码。
我们的解决方案是:仿照 Fumadocs 的实现,自己编写一套对应的自定义组件(如 TrackedCodeBlock、TrackedSearchDialog 等),在这些组件内部统一处理 GA 事件上报。GA 的实际接入目前暂未实施,但相关接口调研已准备就绪。
如果你的文档框架有内置组件,而你又需要在这些组件上做埋点,提前替换为自定义组件是最干净的方案,远比事后改造省力。
八、llms.txt:Fumadocs 已内置
Fumadocs v16 已原生支持 llms.txt,无需任何额外配置。首个文档编译通过后,直接访问 /llms.txt 即可获得自动生成的文档索引。
以我们的站点为例,docs.ckbccc.com/llms.txt 当前列出了所有文档页面的结构化目录,覆盖 Getting Started、Core Concepts、Guides、Packages 四大章节下的完整页面列表。AI 工具可通过该文件快速了解文档站的整体结构,再按需获取具体页面,极大地方便了 AI Agent 对文档的消费。
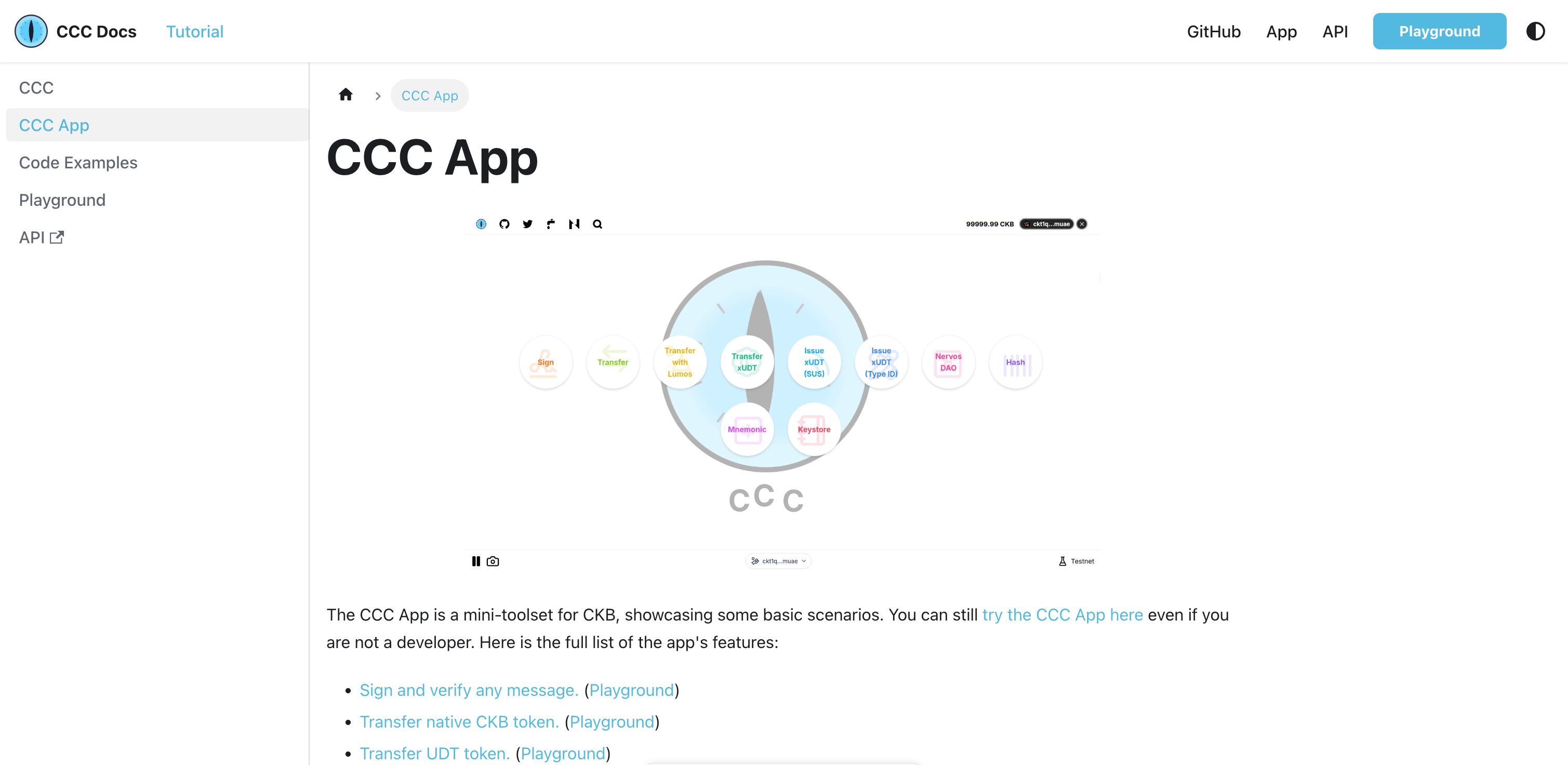
九、现在的文档站长什么样?
经过近一个月的建设,docs.ckbccc.com 已形成从入门到各包详解的完整中英双语文档,共 35 个页面,核心结构如下:
- Get Started
- Introduction
- Quick Start
- Installation
- Core Concepts
- CKB Cell Model
- Signer
- Transaction
- Client
- Address
- Guides
- Connect Wallets
- Compose Transactions
- Sign Messages
- UDT Tokens
- Spore Protocol
- Node.js Backend
- Examples
- Code Examples
- Packages
- CCC Package Guide(汇总导览)
- Core Packages:
@ckb-ccc/ccc、@ckb-ccc/core、@ckb-ccc/shell、@ckb-ccc/connector、@ckb-ccc/connector-react - Protocol Support Layer:
@ckb-ccc/spore、@ckb-ccc/udt、@ckb-ccc/ssri、@ckb-ccc/lumos-patches - Wallet Integrations:
@ckb-ccc/joy-id、@ckb-ccc/eip6963、@ckb-ccc/nip07、@ckb-ccc/utxo-global、@ckb-ccc/okx、@ckb-ccc/uni-sat、@ckb-ccc/rei、@ckb-ccc/xverse
从最初的 4 个文件,到现在 35 个页面的中英双语文档,覆盖了从入门到各包详细说明的完整链路。同时,文档的可用代码片段也从 141 个扩充至 704 个,提升了近 5 倍(查看 Context7),为开发者和 AI 工具提供了更丰富的可引用代码示例。

彩蛋:Packages 导览页的设计
CCC 是一个 monorepo,旗下十几个 NPM 包覆盖核心 SDK、协议扩展、钱包集成等多个维度。开发者最常见的困惑是“我的场景该装哪个包?”。我们专门设计了一个 Packages 导览页,核心做两件事:
- 选型指引:按运行环境(前端/后端)、框架(React/其他)、功能需求(钱包连接/协议操作)将所有包分类,以卡片形式呈现,每个卡片用一句话说明适用场景,让开发者扫一眼即可定位目标包。
- 版本与下载量一览:页面下方以表格列出每个包的最新版本号和近一周 NPM 下载量,通过自定义
<PackageBadges>组件实时渲染 shields.io 徽章,帮助判断包的更新活跃度和社区采用程度。
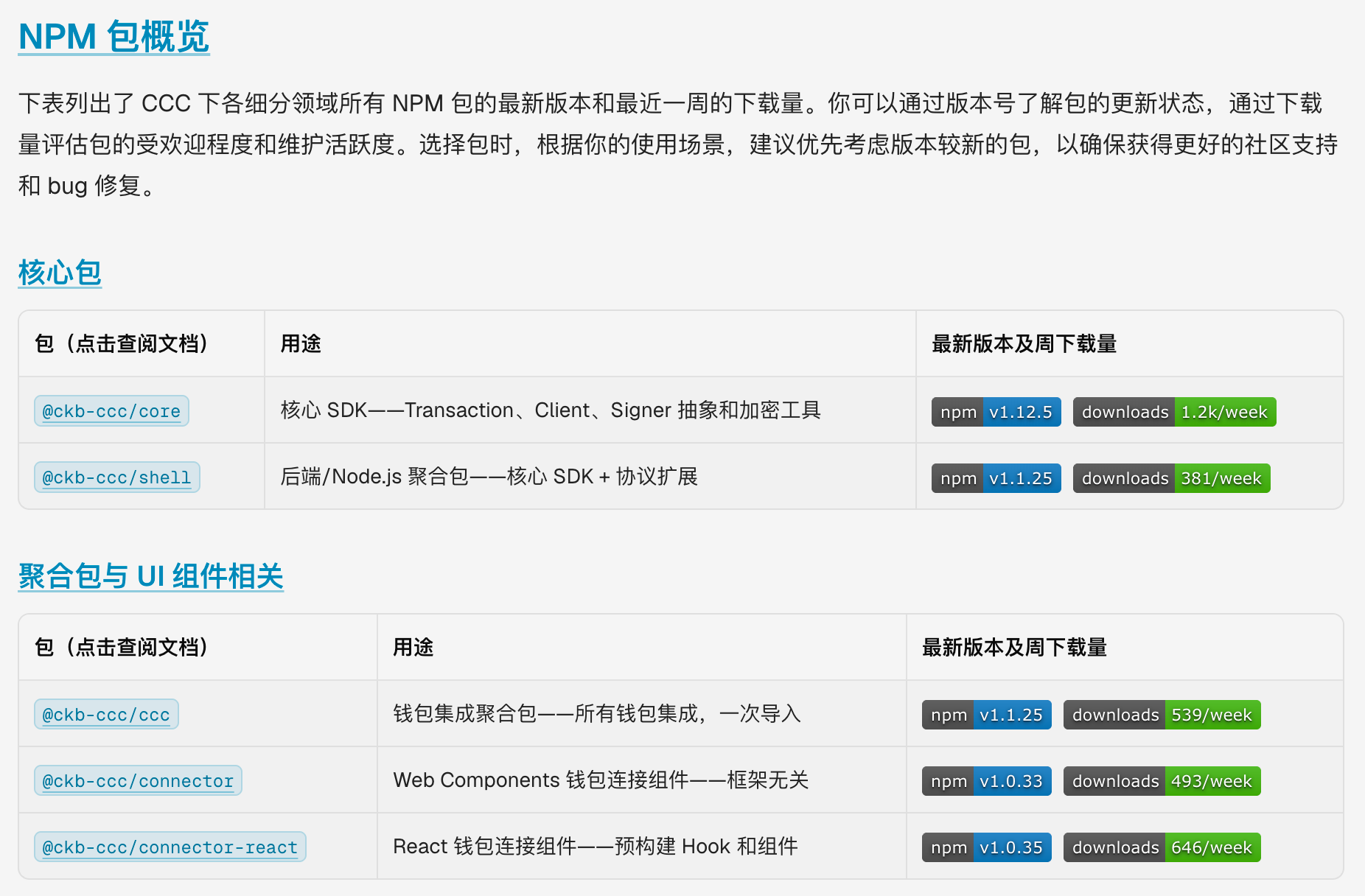
该页面的理念是:让“选包”的决策成本尽可能低——无需翻阅 README 或逐个检索 NPM,一个页面解决所有问题。
十、给其他项目文档维护者的建议
- DeepWiki 是好的 review 工具,但要保持批判性。 它能发现文档与代码的真实差异,但也会犯错,“某方法不存在”这类结论务必去代码里二次确认。
- 翻译规范要从错误中归纳,而非凭空制定。 让 AI 先翻译,人工修正后让 AI 对比两个版本提炼规律——这样得到的规范才真实有效。
- 会话长度是翻译质量的隐形杀手。 长会话中 AI 对早期规范的遵从度会下降,发现质量滑坡立即新开会话。
- 多工具交叉比对 + diffchecker 是处理“怎么翻都不满意”情况的有效手段。
- 如果框架有内置组件,提前换成自定义组件,为埋点做准备。 事后改造远比事先替换麻烦。
- 先 review 英文,再翻译中文。 不要在错误的英文文档上直接做翻译,那样会让修正成本翻倍。
后记
至此,CCC 文档站达成一个里程碑:面向人类开发者的完整文档已然就绪,为 AI 消费文档所做的准备也已落地——从 llms.txt 的原生支持,到代码片段从 141 个扩充至 704 个,这些工作的共同指向只有一个:让 AI 更准确地理解 CCC。
下一步,我们将围绕 AI 发现(AI Discoverability) 与 AI 消费(AI Consumption) 两个方向持续迭代文档设施,使其成为 AI 时代下 CKB 应用开发的首选参考。
CCC文档站地址![]() :docs.ckbccc.com,目前支持中英双语。如果你在使用过程中发现内容错误或有改进建议,欢迎在 GitHub 提 issue 或在此留言告诉我们。
:docs.ckbccc.com,目前支持中英双语。如果你在使用过程中发现内容错误或有改进建议,欢迎在 GitHub 提 issue 或在此留言告诉我们。