CKB-NFT Draft Spec
Introduction
This document is divided into two parts. Part 1 describes some background details as well as a less formal discussion about designing token standards in general, the concept of interoperability, and other relevant concepts. Part 2 contains the CKB-NFT specification itself. Part 3 is about the rationale for specific design decisions.
Non Fungible Tokens (NFTs) are tokens that are not interchangeable or necessarily of equal value, even if they are within the same token class. This includes digital collectibles, game items, and records of ownership of physical assets.
Part 1
A note on granularity
Months ago, I made a post about the way I think about token standards. One of the main points that post was making (in many more words than necessary) was that token standards have two main objectives: to provide a well-defined set of behaviors & properties that any standard-compliant token will implement, as well as a minimum set of implementation details such that it is easier for all third parties that make use of the standard to easily support it. The latter point is crucial for enabling interoperability.
There are two goals that come to mind when thinking about interoperability. First, that any system that already supports one token is easily able to support a second token described by the same standard. So, if a wallet supports one CKB-NFT, it should be easy for the wallet developers to support a second CKB-NFT without changing many implementation details. Second, both off-chain and on-chain systems should be able to use an instance of a standard-compliant token in novel ways and in vastly different contexts. For example, the ideal would be that the same token could be traded in a DEX, integrated with a lending protocol, and deposited as collateral for a stablecoin, all without breaking the standard-compliance of the token.
These may not necessarily be “interoperability” concerns in a strict sense of the term, but they are crucial priorities that come to mind when I think about how to operationally define interoperability goals for token standards.
From Platform Agnostic to CKB-Specific
This specification (and other token standards) actually describes a token from multiple levels of abstraction (as does the SUDT proposal, though it doesn’t make the distinction between these levels of abstraction as explicit).
At the highest level, the standard describes the NFT in CKB-agnostic terms, using more or less established conventions that have emerged in the industry.
To describe NFTs in any more detail requires defining the NFT within the context of CKB’s programming & state model. For example, we could establish that an NFT instance is a cell with a type script that references an NFT definition. At this level of abstraction, a description of the NFT design is coupled with CKB technology, but is compatible with multiple implementations that may not be interoperable.
To enable interoperability requires an even further degree of specificity, where a minimum set of unambiguous details are put forth & agreed upon, such that all specification-compliant implementations are interoperable. This is illustrated in the diagram below.
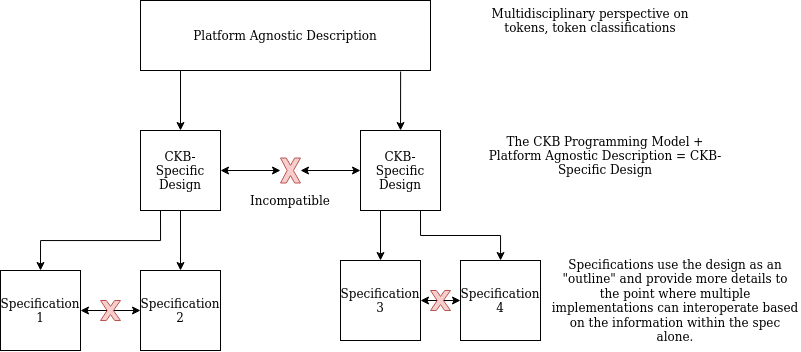
It would be beneficial later on to establish more formal specifications of various assets based on a meta-model that specifies the CKB programming model and allows us to easily design & specify new CKB-systems.
Part 2: NFT-CKB Specification
The NFT-CKB Specification covers the relevant data structure(s) of any NFT implementation as well as the operations that an implementation must support. In CKB-specific terms, specifying the data structures involves detailing the relevant cells, the schema of a cell’s fields & their meaning. Specifying the operations involves doing the same thing but for transactions instead of cells.
Data Structures
NFT-Instance
NFT Token Instance: Cell Schema + NFT Semantics
data:
id: 32_bytes
type:
code_hash: NFT Definition Cell Hash
type_hash: code | type
args: governance_lock_hash, [other args], *
lock: <user_lock>
Just like in SUDT, the code_hash of the token instance’s type script references the definition (or “code”) cell that implements the NFT verification logic.
The first arg in the type script is treated as the governance lock hash . This is important because, in many use cases, there may be some set of participants with additional permissions enabled, such as the permission to mint a new set of tokens representing limited edition collectibles. Further, it acts as an attestation by the “governor(s)” of the NFT instance’s validity.
The ID in the data field is universally unique and permanent. The ID is implemented as the first 32 bytes of the data field.
NFT Rules abbreviated:
- The first 32 bytes of the NFT instance’s
datafield must be occupied and represent the NFT instance’s ID - The first 32 bytes of the
argspassed to the NFT instance’s type script must be occupied and equal the governance lock hash (explained later) - Each NFT class must have a unique Type ID, which is derived from the hash of the instance’s
typefield. Therefore, two NFT instances with the same type hash are regarded as two NFT instances of the same class.
Operations
- Generation
- Transfer
Generation
First, I will talk about generation, or the act in which a specific NFT instance is produced. This includes the modification of an NFT (which can be thought of as the act of producing a new version of a previous NFT instance). There are many ways to design this functionality. To learn about the trade-offs of different approaches & why the following approach was proposed, refer to part 3.
The goal here is to ensure that each newly created NFT instance has a unique ID, while also minimizing the transaction size and enabling batches of NFT instances to be constructed within a single transaction.
For any newly created NFT instance in outputs at index
i, thehash(seed_input.tx_hash, seed_input.index, i)must equal the first 32 bytes of the NFT instance in outputs at indexi.
This enforces uniqueness because each output has a different index. It also minimizes the size of transactions by making the lower bound of inputs a constant of 1 rather than a lower bound that grows linearly with the number of NFT instances in outputs. It also allows for multiple NFT instances to be generated within a single transaction.
Inputs:
Cell Locked w/ Governance Lock:
Data: <... user defined>
Type: <... user defined>
Lock:
code_hash: governor_lock_code_hash
args: governor_lock_args
type_hash: type | code
[NFT Cell
Data: Instance ID
Type:
code_hash: NFT Definition Cell
args: governor_lock_script_hash, [...]*
Lock:
<user_defined>
,...], *
Outputs:
[NFT Cell
Data: Instance ID
Type:
code_hash: NFT Definition Cell
args: governor_lock_script_hash, [...], *
Lock:
<user_defined>
,...], *
Constraints:
- One input cell must be locked with the governance lock such that
Hash(input.lock) == governor_lock_script_hash - The first 32 bytes of each NFT instance’s data cell - at index
i- in outputs must equalhash(seed_input.tx_hash, seed_input.index, i)OR have a corresponding input cell w/ same ID.
In some cases, a specific NFT may need to enable users to combine and create new tokens (e.g., cryptokitties) while in other cases, the creation of new tokens is a capability reserved for certain, permissioned agents such as the developers (e.g., a trading card game). It is not obvious at first glance whether the generation operation is flexible enough to support these various use cases, but it is. See Part 3, subsection titled “NFT Generation Extensibility” for details about this.
Transfer
Inputs:
[NFT Cell
Data: Instance ID
Type:
code_hash: NFT Definition Cell
args: governor_lock_script_hash, [...], *
Lock:
<user_defined>
,...], +
Outputs:
[NFT Cell
Data: Instance ID
Type:
code_hash: NFT Definition Cell
args: governor_lock_script_hash, [...], *
Lock:
<user_defined>
,...], +
Constraints:
- For each NFT cell in outputs, there must be an NFT cell in inputs with the same ID
- The data field of an NFT cell in outputs must match the data field of its corresponding input
Note that this does support burning, or destruction, of an NFT instance. You could optionally add the rule that each NFT cell with ID in inputs has exactly one NFT cell in outputs with that ID to prevent NFT destruction.
Part 3: Design Decisions
Token Metadata
In theory, an NFT is distinguished from a fungible token in only one specific way: the presence of a token-instance-specific identifier. In practice, many NFT specifications and implementations on other chains are also accompanied with token-instance level metadata. This metadata tends to be stored partially on-chain and partially off-chain. The on-chain portion tends to contain, at least, a reference to off-chain metadata. This allows on-chain space to be preserved, while still acting as a trust root for the integrity and validity of the off-chain data by way of attestation and verifiability.
Metadata is not detailed in this NFT specification. The particular requirements of token metadata may vary widely depending on case-specific details (a collectible will have different requirements than real estate) in terms of schema, data resolution strategies, and verification. Many projects couple the metadata standard with a specific off-chain protocol such as IPFS. This is is detrimental because standards that operate on layer 1 should be self-contained. More generally, dependency between lower layers and upper layers should be unidirectional, from upper to lower.
NFT ID Generation Patterns
To produce a unique ID, a straightforward approach would be that, when a user initially acquires the NFT instance, or when a new NFT instance is created by a dapp, the cell in the transaction’s outputs that represents the NFT instance could use the hash of the first input in the transaction as its ID (a common pattern we refer to as “seed cell”). This works because the script would ensure the following two rules:
- If an NFT instance exists in both input and output, the IDs must match
- If an NFT instance exists only in output, its ID must match the hash of the first input
The first limitation of this approach is that one NFT instance at most could be created per transaction. This is not ideal because, as a settlement layer, it is probably the case that operations performed on-chain will be aggregates of many off-chain operations, which is a common usage pattern.
A modification of this design that handles this would be: for any newly created NFT instance in outputs at index i , there must be an a cell in inputs at index i and the hash of that input must match the first 32 bytes of the NFT’s data field in outputs.
This would enable creation of multiple NFT instances, but incurs a new cost: the transaction size grows proportional to twice the size of the NFT instances in the outputs.
The solution presented in part 2 takes the best of both the above-mentioned approaches: unique IDs w/o incurring the cost of linear growth of the transaction’s inputs.
NFT Generation Extensibility
The generation pattern is extensible enough to support a variety of different use-cases. Remember that the specification prescribes a minimum set of rules for an implementation. This act of constraining the possible approaches provides predictability and interoperability, while also making development easier by providing a minimal starting point.
Extending the standard involves two procedures: describing the additional logic and implementing that logic, affected by the specification’s “logical extensibility” and “implementation extensibility”, respectively.
A specification is logically extensible to the extent that additional rules can be added to an instance of the specification without violating the pre-specified rules or its design goals.
A specification’s implementation extensibility is inversely proportional to the difficulty involved with implementing the logical extensions within the context of the pre-specified minimum implementation details. Related to implementation extensibility is flexibility, which in this context describes how easy it is to modify the implementation details post-deployment.
With those abstract points out of the way, let’s think about specific use cases. Imagine that two different projects are building an NFT. Project 1 requires users to be able to combine NFT instances in novel ways to produce new NFT instances. An example of this usage pattern is the act of “breeding” in the cryptokitties project. Project 2 requires that only a certain set of users with additional permissions - admins - are able to produce new NFT instances. An example of this usage pattern is the act of releasing limited edition packs in a trading card game.
The Generation operation specified in part 2 supports multiple ways to design & implement this functionality. The first obvious way is to include the logic directly in the type script of NFT instances. The second way would be to rely on the governance lock .
Both approaches have trade-offs and the decision depends on the priorities and circumstances of the specific project. For example, if the custom functionality is implemented pre-deployment and the project members determine that this logic is unlikely to change in the future, it may make sense to add it to the type script. The benefit of this approach is its simplicity. The type script is the primary workhorse of the token and the governance lock script remains as simple as possible. If more than one script is responsible for a portion of the system’s logic, it becomes more important to define and understand the boundaries between the scripts and how their presence in the transaction changes the behavior of each. An example of this pattern - inter-script signalling - can be found in the reference implementation The code in that script conditionally enforces logic based on the presence or absence of an input locked with the governance lock.
If, on the other hand, the custom functionality is implemented post-deployment, or is likely to change, then it may make more sense to utilize the governance lock. Minor bugs with the governance lock are probably less crucial than minor bugs within the type script (since the type script, after all, is attached to every single NFT instance). Adding changes post-deployment to the governance lock isolates the risk of introducing new and minor bugs. Further, it may be a priority to keep the core logic in the type script immutable. Updating the type script’s code later adds a further challenge: if NFT instances reference the type script by data hash, then changes to the type script’s code will change the data hash, breaking references. So, it would be essential that the type script is referenced by type hash instead.
Conclusion
The NFT spec put forth here is pretty simple. There are many possible ways to specify a CKB-based NFT. The design presented in this document is tailored for interoperability, aggregated transactions, simplicity, and flexibility.
I hope that this generates discussion and experimentation amongst developers so that we can determine the effectiveness of this design in terms of those goals.
Acknowledgements
I want to thank members of the developer relations & community operations teams, including Jordan Mack, Thomas Spofford, and Matt Quinn, for providing substantial feedback and review.